
Introduction
Tabular provides a centralized layer of security for your Apache Iceberg tables with regard to how various compute engines access those tables. Tabular implements that access through the use of credentials. There are several types of credentials. This blog focuses on the most often used:
- Service credentials
- Member credentials
There’s also an IAM authorization available that enables you to link AWS IAM Roles to Tabular Roles. But that’s a topic for a later blog.
First, let’s do a quick review of a Tabular Organization.
Tabular Organization
The top-level in Tabular is an organization. Within that organization, there are members and roles on one side, with warehouse, database, and tables on the other. Roles dictate a member’s ability to access tables. This basic architecture diagram provides a quick overview of those components, though it does not illustrate the relationship between members/roles and data.
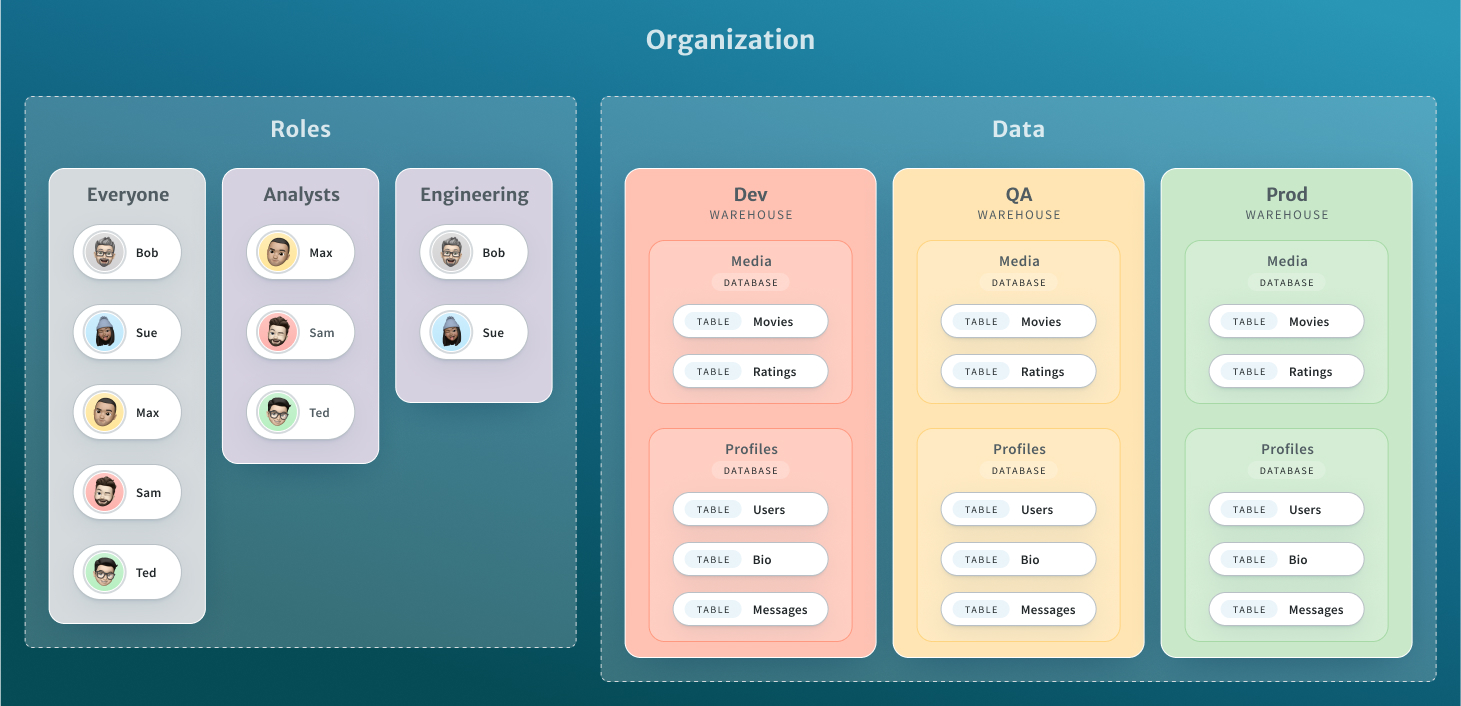
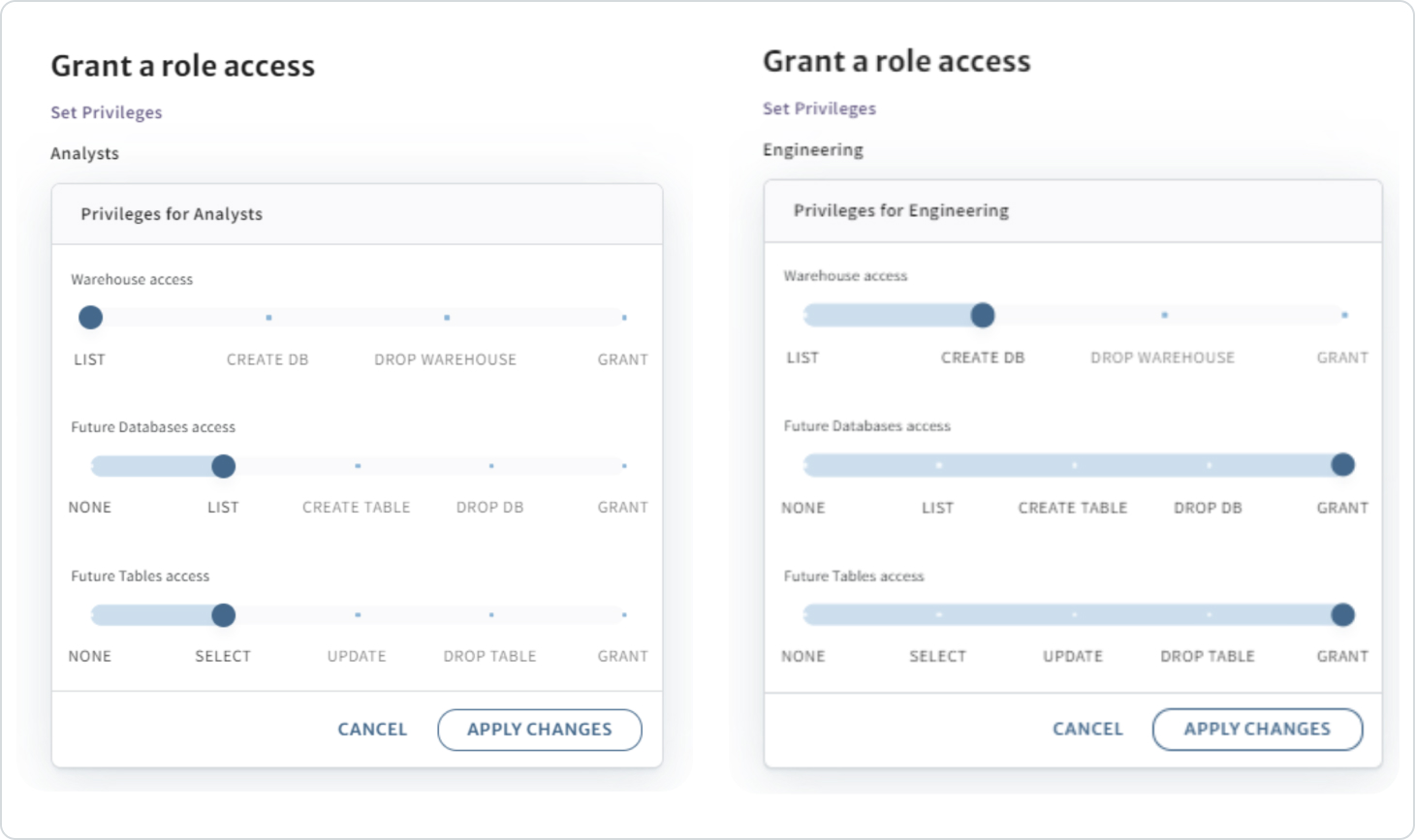
You control access by using a role at the warehouse, database, or table level. In the following example, we see the Analysts role has read access at the warehouse level, which applies to any database or table created in the future. The Engineering role has full permissions, other than changing existing warehouse access.
Roles
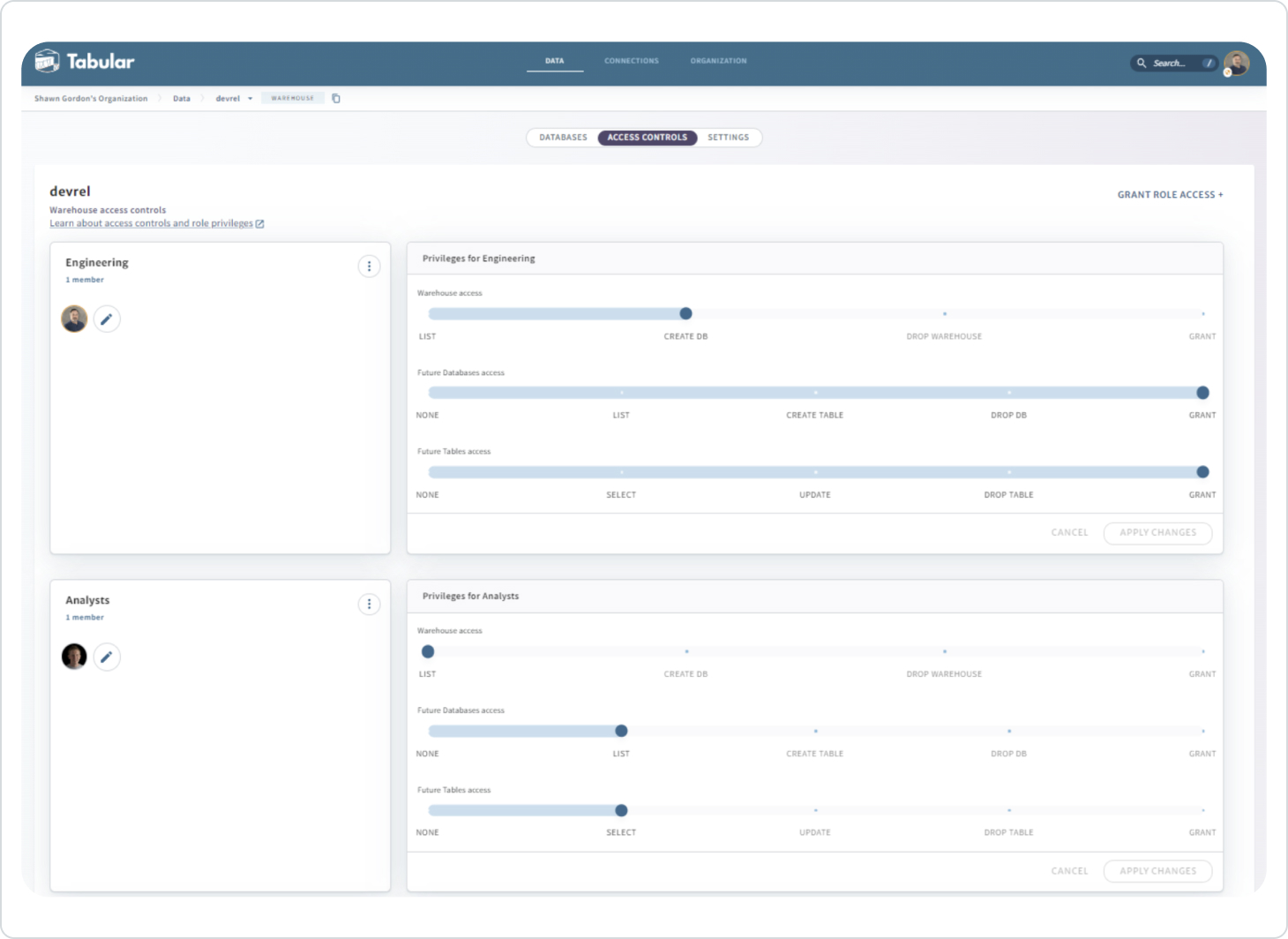
It’s typical to define roles around job function, then assign members to those roles. It is the role that controls members’ access to the data. The permissions model should feel very similar to that of a relational database system. Here, for example, we see the roles that exist for the devrel warehouse, which includes the two roles we just granted access to.
Using our organization diagram as the basis, Tabular allows you to create different roles for each warehouse for the same user. For example, Bob can be a member of 3 different Engineering roles, each of which has different permissions to each warehouse, so he can:
- Read/write and drop/grant on Dev
- Read/write on QA
- Read only on Prod
Note: Permissions are additive; if a member is in multiple roles that apply to the same data, that member’s permissions are a union of all the roles.
Credential usage
Member credentials
In Tabular, a member credential represents an individual member. Our typical member Bob, for example, can create his credential, name it, deactivate it, or delete it. Member credentials can be used with various compute engines, here is an example of configuring Spark to use a credential. In that case, the credential can be used as follows:
bin/spark-sql `
--packages org.apache.iceberg:iceberg-spark-runtime-3.3_2.12:1.3.0,software.amazon.awssdk:bundle:2.20.18 `
--conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions `
--conf spark.sql.defaultCatalog=devrel `
--conf spark.sql.catalog.devrel=org.apache.iceberg.spark.SparkCatalog `
--conf spark.sql.catalog.devrel.catalog-impl=org.apache.iceberg.rest.RESTCatalog `
--conf spark.sql.catalog.devrel.uri=https://api.tabular.io/ws/ `
--conf spark.sql.catalog.devrel.credential=<YOUR TABULAR CREDENTIAL> `
--conf spark.sql.catalog.devrel.warehouse=devrel
To be clear, when configuring an engine like Spark with a member credential, the engine will act with the capabilities and permissions of that member. That means that any role the member is part of will dictate the privileges available to the credential. Tabular’s access control functionality will ensure this. A best practice, however, is not to use a credential that is tied to a member in production jobs. If the member is removed from the Tabular organization or the permissive role, their associated credentials will stop working.
This capability is especially valuable, as it enables you to provide security around your data which Spark process that in and of itself is not inherently able to.
Service credentials
The service credential is intended to be used with long-running services, such as Trino or Airflow, that need to potentially act as multiple users. With a service credential, you have the ability to control access per session in different ways.
For example, you can start up Trino with the service credential; then, as you connect to Trino, you can provide an identity you want to use. Tabular will then use that identity to resolve it to a member of the organization and subsequently acts as that member for that session with whatever privileges available in the roles that the member is part of, just like the member credential.
To explain that in a little more detail, let’s say, for example, you launch Trino with the following service credential: \
docker run \
-name trino-tabular \
-p 8080:8080 \
-d \
-e TABULAR_CREDENTIAL= <YOUR TABULAR SERVICE CREDENTIAL> \
-e TABULAR_CATALOG_URL=https://api.tabular/io/ws/ \
tabular/trino
The connection between the Trino server and Tabular has been established. Next, we want to log in as a member who’s been defined in the Tabular organization – in this case, a member with read/write access called bob@tabular.io
docker exec -i -t trino-tabular trino -catalog mycat --user bob@tabular.io
Now, Trino will impersonate bob@tabular.io for the duration of the session.
Managing Tabular credentials
Tabular provides a quick way to name and create a credential; you can also use one of the wizards that are currently available for Spark, Trino, or Starburst, which walk you through other specific steps and provide a run string with all your data embedded, similar to the Spark example above.
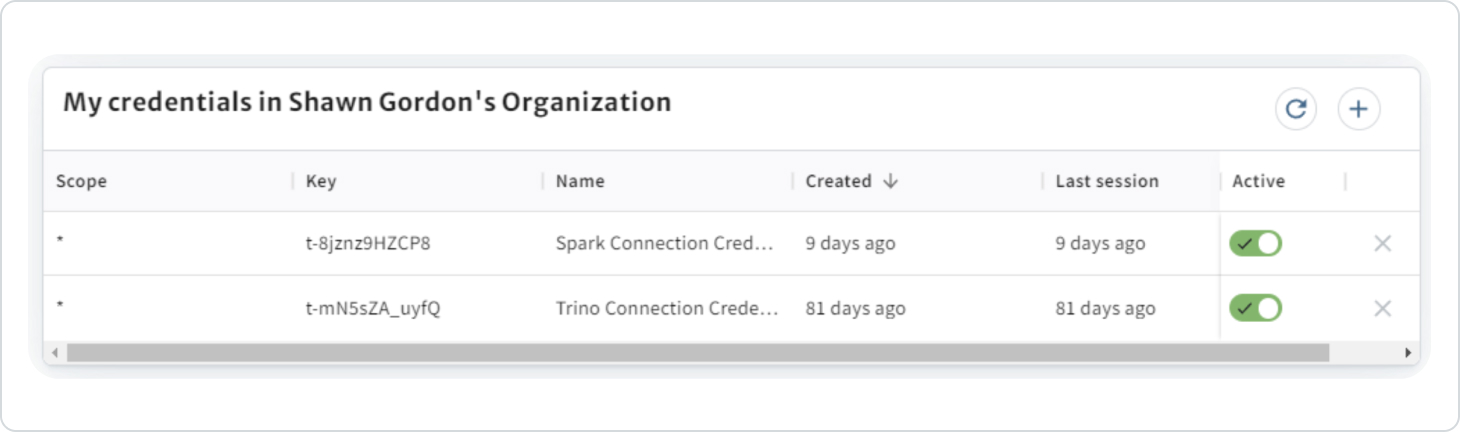
Each member creates their own credentials. The credential view from MY PROFILE displays your member credentials, lists credentials available to you, and enables you to deactivate or delete credentials.
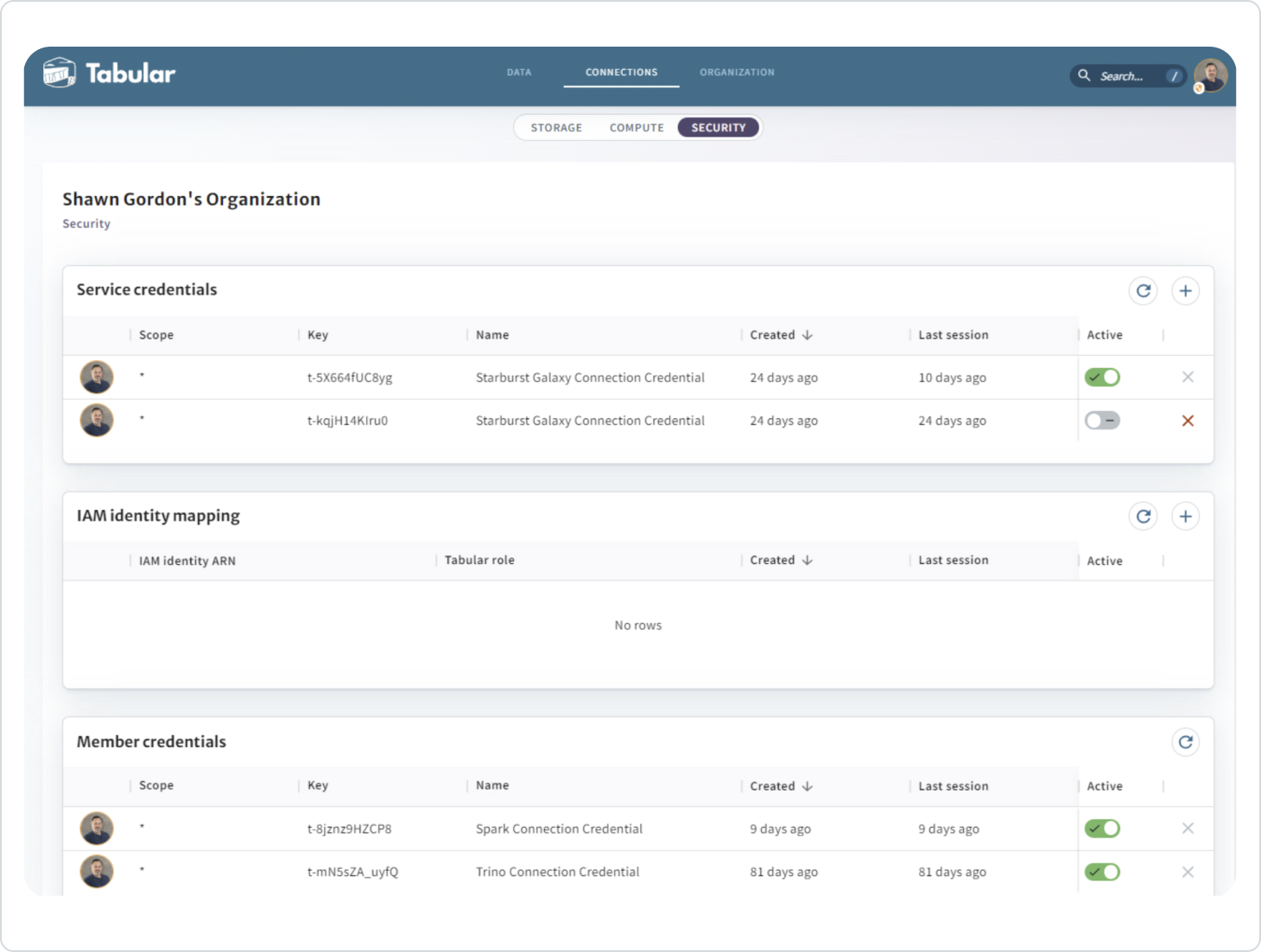
The SECURITY page, which is available only to a SECURITY ADMIN in Tabular, also includes the Service Credentials and the IAM Identity Mapping (which will be covered in a subsequent blog):
Summary
The combination of member and service credentials provides for a flexible and powerful combination of access controls. This granular security enables you to apply security controls on the data without relying on the compute engine to be properly configured.
Next time we’ll dive into IAM identity mapping and the additional controls it provides.


