
- The growing need for a secure data lake
- Role-based access control for data
- Mission (Im)possible: RBAC for the data lake
- Tabular’s approach
- What about Apache Ranger?
- Summary
The growing need for a secure data lake
We’re experiencing two powerful business trends that seem at odds with each other: more workers are using more data in more ways to deliver value to their employer, while at the same time regulations and consumer expectations around data privacy, governance, and compliance are sharply increasing. It’s like adjacent tectonic plates sliding in opposite directions. This puts an organization’s data leaders in a very challenging position. How do they deliver on expectations that data must provide ever more value to the business while at the same time ensuring they do not expose the company to massive risk?
A 2022 report from IBM found that the average cost of a data breach in the US was $9.4M. And of the companies covered in the report, more than 83% had at least one data breach.
In this series of posts, we outline best practices for taming the complexities of securing next-generation data architectures and also highlight some common anti-patterns.
- Part I – Secure the data, not the compute
- Part II – Implementing least privilege access
- Part III – Role-based access controls (you are here)
Role-based access control for data
For access controls to scale and work effectively for data lakes, we need a way to effectively represent privileges in a way that matches our mental model — namely databases, tables, and the teams or other organizational groupings of people that require specific data access to do their jobs.
To regulate an individual user’s access to data based on their role in an organization, security teams typically use Role-Based Access Control (RBAC). RBAC is the industry standard for managing user data. RBAC allows for the efficient creation, modification, or discontinuation of roles as an organization’s needs change over time without the burden of updating individual user privileges.
In role-based access control (RBAC) systems, security policy is defined by granting privileges on resources to roles.

In turn, roles are granted to individuals or systems to perform activities in the data lake. You can also nest roles – have roles granted to other roles – for more flexible access policy.
Another important RBAC feature is the concept of delegation. Delegation makes it possible for a role to grant a limited set of privileges to other roles. For example, someone with a finance admin role can grant or revoke privileges for financial data to other roles, but they cannot grant privileges to security data. This enables distributing access control policy responsibilities across an organization to the data owners who have the necessary context to make informed decisions.
Mission (Im)possible: RBAC for the data lake
Implementing a role-based access control system for data lakes is deceptively challenging. First and foremost, very few examples of such systems even exist, and those few that attempt to provide these capabilities have severe limitations (Apache Ranger in particular – more on that below). As a result, most organizations end up with a mixture of secure compute where possible (for example Trino, which violates secure storage, not compute) and broad access to data files where it isn’t (for example Spark, which violates the principal of least privilege). The risk this scenario presents is no longer acceptable; data products have become too valuable, and the cost of data breaches] is too high.
If the goal is to secure storage with granular controls, then you may be tempted to implement RBAC by syncing policy down into the object store as file or prefix permissions. The following sections highlight the difficulties of that approach.
Translating between tables and files
One of the trickiest aspects of implementing RBAC systems for data lakes is that, while our privileges are all about databases and tables, the primitives we have to work with are all about files and file systems (in accordance with our best practice of secure storage, not compute).
We must translate logical operations such as SELECT on TABLE to file access policies such as GET on FILE. Let’s use our example from above – granting SELECT access on the signups table to the marketing role using AWS IAM policy.
"Statement": [{
"Effect": "Allow",
"Action": ["s3:GetObject"],
"Resource": ["arn:aws:s3:::myBucket/wh/kpis/signups/*"]
}]
Simple enough. Now let’s try adding CREATE TABLE access to all the tables in the KPIs database. It seems natural to include additional actions and update the bucket path to be less granular.
"Statement": [{
"Effect": "Allow",
"Action": ["s3:GetObject","s3:PutObject"],
"Resource": ["arn:aws:s3:::myBucket/wh/kpis/*"]
}]
While this accomplishes our primary goal, it also has some unintended side effects. For example, this policy would also allow anyone in the role to MODIFY all existing tables in the database. To achieve the level of permissions that we expect from SQL, RBAC requires a complex web of Allow and Deny statements for every possible prefix and role combination. And seemingly simple changes to those permissions in logical table space can easily spiral into thousands of file access policy changes. Auditing and reasoning about that much policy is simply unsustainable at scale.

Scaling data authorization decisions
An alternative to managing static object policy is to handle authorization requests dynamically. A single Spark or Trino query might request access to hundreds of thousands of files across thousands of executors. And hundreds or thousands of these queries can be running in parallel (thank you, dbt). The authorization system must have incredibly high throughput and low latency to ensure job performance isn’t impacted. This type of system typically requires multiple dedicated engineering resources to build and operate.
The who – what – when of data security policies
In any access control system, we must be able to audit changes to the security policy over time, along with all of the authorization requests and details as to why access was or was not granted. For data environments, we want that audit history to tell us the identity of the requestor (the individual user as opposed to an assumed role name) and what logical data set they were accessing (that is, database and table as opposed to file path).
Tabular’s approach
In part I of this series, I explained how Tabular secures the data at the storage layer. That means our RBAC policies apply universally across compute engines. In part II, I discussed how Tabular gives you a variety of ways to provide the identity of the person or system requesting access to a given data resource.
The final piece of the puzzle is our role-based access control system for defining and enforcing access controls on top of Apache Iceberg tables. This enables you to create and manage roles, role memberships, and their associated privileges. And it includes the ability to leverage role-nesting and delegation of authority to grant and revoke decisions at multiple levels.
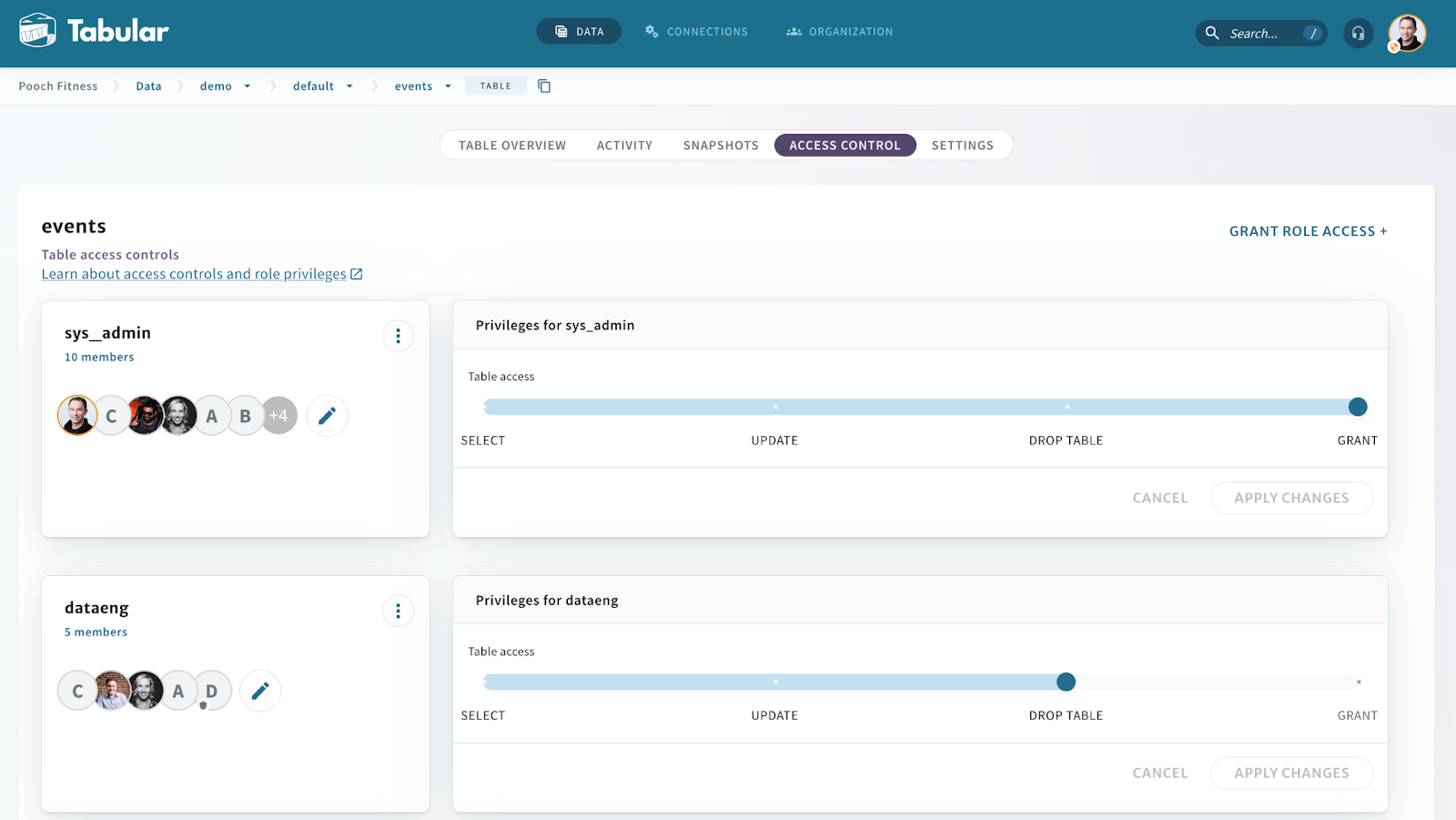
Tabular makes setting and inspecting table-level access control policy simple and intuitive. You can also manage users, roles, and access policies through a REST API, Terraform module, or syncing platforms such as Okta (using SCIM).
In addition, Tabular provides a fully-managed authorization service to handle policy enforcement. This service acts as a singular, centralized place for authorization decisions across any number of compute engines. It leverages a system of JWT tokens and request-level caching to achieve response times of less than 10 milliseconds.
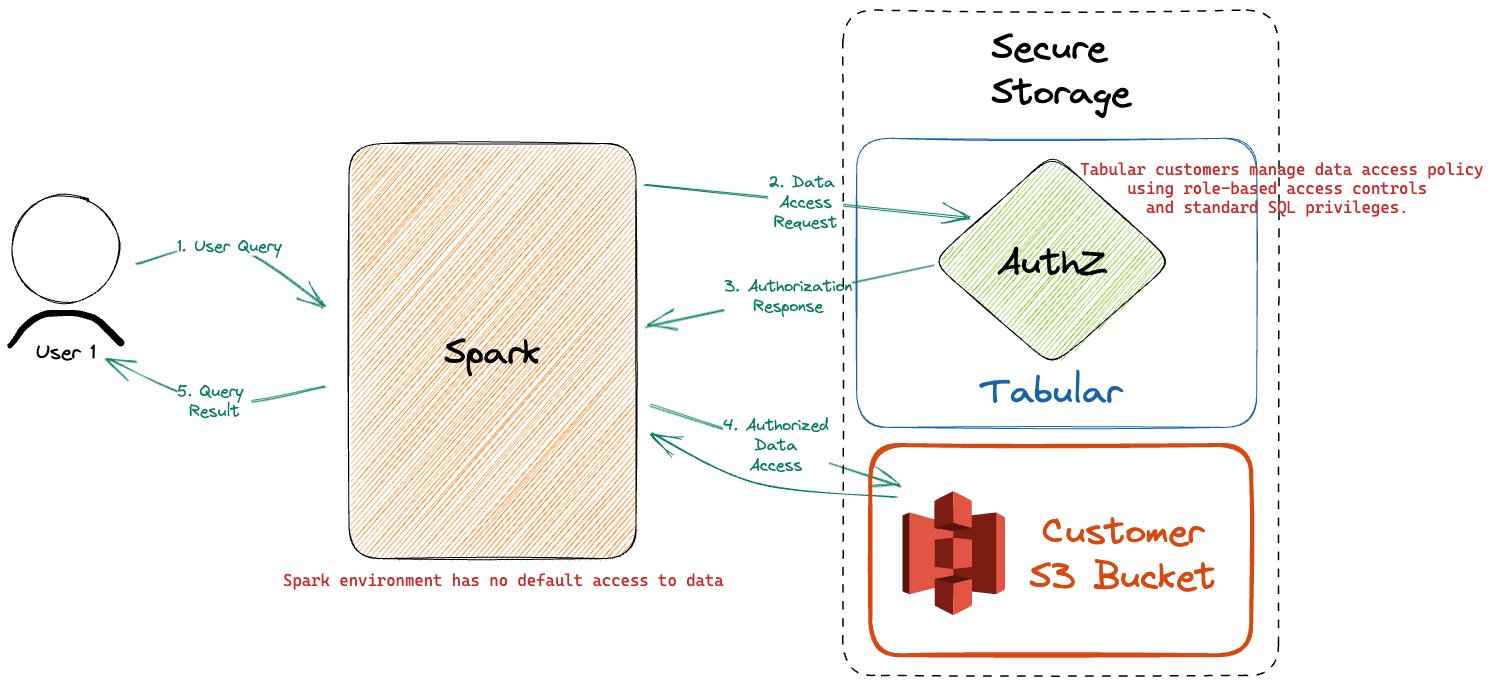
Perhaps most importantly, because all data access is governed by a central policy and authorization service, the Tabular platform is able to provide a comprehensive, consolidated audit log of exactly who used or modified what data and when they did so.
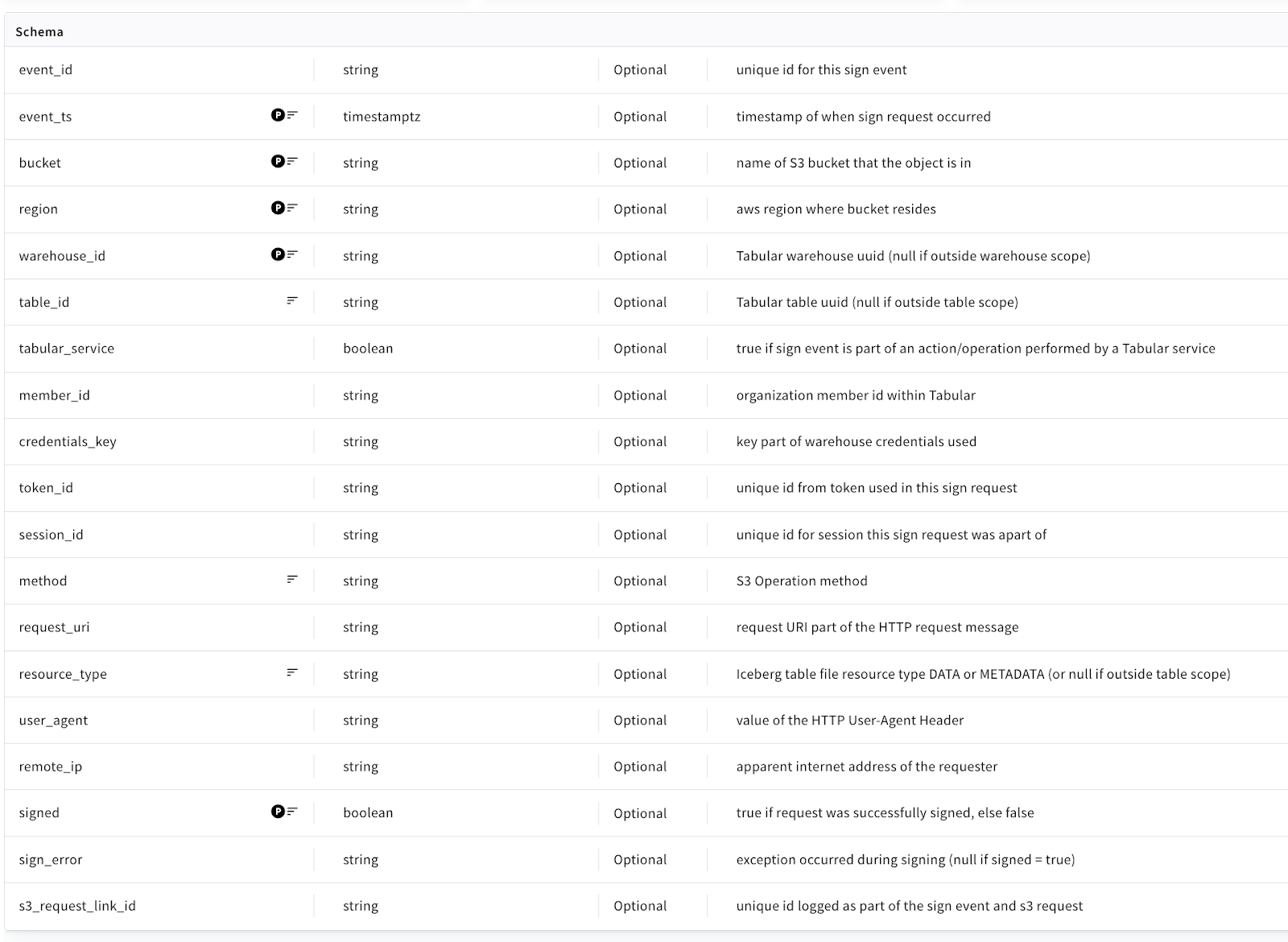
Tabular’s security audit log table schema
As you can see, that audit log is delivered to Tabular users as a fully-managed Iceberg table. (Of course, we use the Tabular platform internally to build and deliver data products for our customers!)
Additional Resources
What about Apache Ranger?
Earlier in this post, I mentioned that existing attempts to provide role-based access controls in the data lake space have severe limitations. Apache Ranger is a common example of such a system. Let’s examine some of the ways in which Ranger falls short of our requirements.
Ranger secures compute instead of storage
This violates the best practice from part I. The base architecture of Apache Ranger stores access policy centrally and then uses a client deployed alongside the query engine for policy enforcement. Using Ranger to restrict access to a table in Hive or Trino requires running the Ranger-specific plugins in those systems and doesn’t actually restrict access to the underlying data files. And while you can also use Ranger to restrict access to a Hadoop File System (HDFS), those two sets of policies are independent and have no concept of how the logical tables and data files are related.
Ranger is not universal (for example, it does not support Apache Spark)
This is related to the first problem since there is no Spark-specific plugin to enforce Ranger access control policy. This type of gap is where companies typically just open up broad, direct access to the underlying storage system for certain users and use cases. This violates the best practice from part II.
Summary
Technical hurdles have, up to now, prevented data practitioners from applying RBAC to data lake objects. Such hurdles include:
- Mapping table permissions to objects
- Syncing the corresponding changes to bucket policy
- Database concepts that have no corollaries in object stores, like CREATE permission for a schema
- Scaling to thousands of tables and roles and billions of authorizations
Tabular’s approach to these hurdles is to layer an RBAC system on top of Apache Iceberg tables. This makes it both possible and straightforward to
- Create and manage roles and role-based privileges at the table level
- Universally apply access policies
- Provide a comprehensive audit log of database activity
This is part III of a series of posts where we explore the challenges and best practices around securing data in next-generation data lake architectures. In the next post, I’ll cover the governance aspects of data lake security and how to effectively implement them in an organization. Prior posts in this series include:

