Tabular CDC lets you create a near-real-time mirror of database tables in Apache Iceberg, making important operational data available to analysts, data scientists and AI models.
- We support AWS DMS and Debezium sources, via change log monitoring so as to not load the source database
- Data is delivered in near-real-time (minutes)
- Table-specific optimizations are applied during ingestion. These improvements can greatly reduce the size of the data – and thus query speed and cost.
- Schema inference and evolution. New columns are automatically added to the mirror table, field types are automatically inferred, and dropped columns are retained.
- We maintain an accurate historical record that can be used for streaming.
- Serverless operation – CDC pipelines are based on simple, declarative configuration. They require zero infrastructure, orchestration, engineering, or maintenance.
- Avoids “double update” problem – combines a MERGE operation with a “valid through” transaction ID to ensure no lost transactions.
Other things you should know about Tabular CDC
- UI or API-based configuration (e.g. using Terraform)
- Tabular RBAC restricts mirror table access to users with proper permissions.
- Observable pipelines – Tabular supports the Open Metrics API to expose ingestion activity to 3rd-party observability tools. You can monitor and alert on pipeline latency and errors,
- Transparent, predictable pricing. Pricing is pay-as-you-go and is based on the total number of bytes read to apply changes to the mirror table. You never have to worry about cluster size, handling bursty workloads, or paying for idle compute cycles.
- User-defined data freshness – CDC pipelines can be configured to update target data more or less frequently making it easy to trade-off cost vs latency.
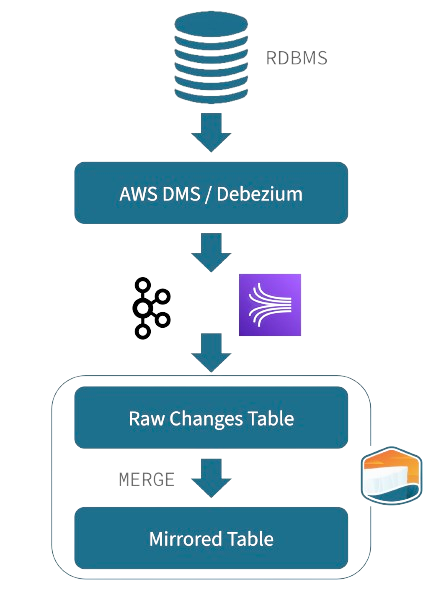
Tabular loads data into a raw change table and then merges those new rows into the target mirror table.