
- Motivation
- Principle of Least Privilege for Data
- Identity, Identity, Identity
- Tabular’s Approach
- Summary
Motivation
Seemingly every day, more people across the business are using more data in more ways to deliver value. At the same time, regulations and consumer expectations around data privacy, governance and compliance are steadily increasing. This puts an organization’s data leaders in a very challenging position. How do they deliver on expectations for data to deliver ever more value to the business while at the same time ensuring they are not exposing the company to massive risk?
In this series of posts, we will outline best practices for taming the complexities of securing next generation data architectures while also highlighting some common anti-patterns.
- Part I – Secure the data, not the compute
- Part II – Implementing least-privilege access (you are here)
- Part III – Role-based access control
Principle of Least Privilege for Data
In part I of this series, we covered the importance of securing the storage layer instead of trying to lock down multiple compute engines one by one. In this post, we’ll focus on the second best practice: people should only have access to the data that they need to perform their job.
This is commonly referred to as the Principle of Least Privilege (PoLP).
To illustrate, let’s examine a real-world example.
Alex, an analytics engineer, owns an ETL job that runs Apache Spark to populate our company’s Customers table.
Alex is also often asked to perform ad-hoc analysis of the customer data to help the product team better understand customer behavior.
In this scenario, Alex requires read-and-write access to the Customers table when running the ETL job and read-only access to the Customers and Revenue tables while doing ad-hoc analysis using Trino.
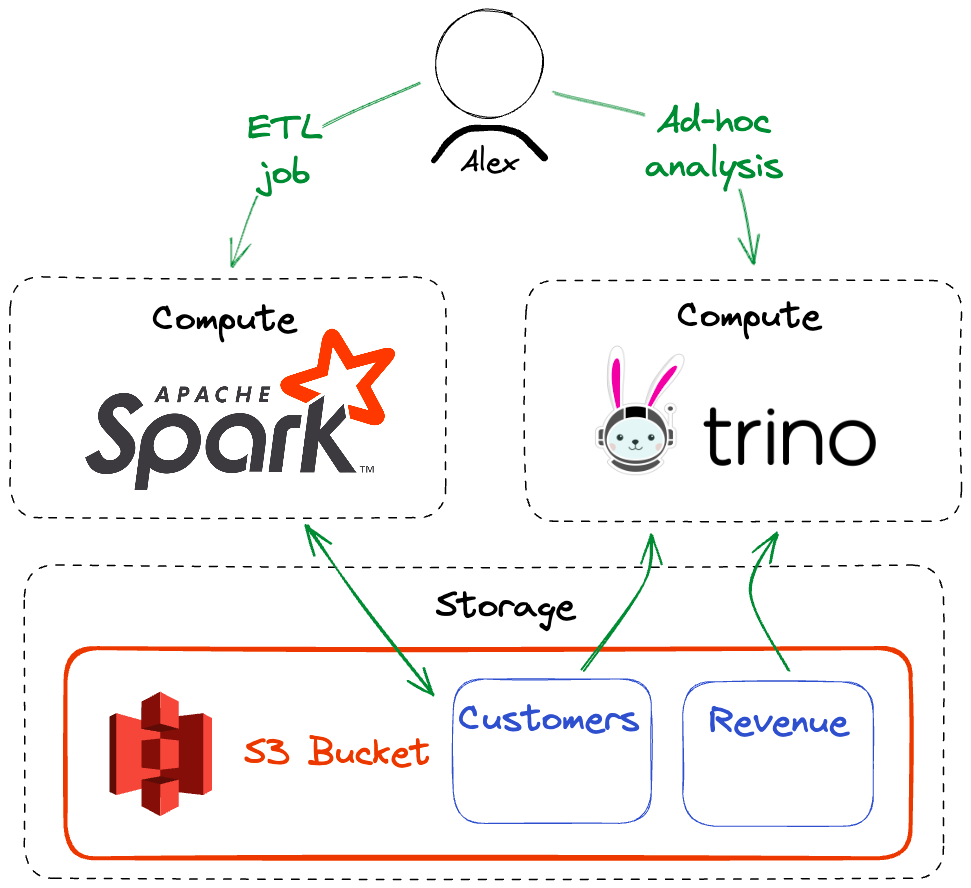
To apply the principle of least privilege to our data, a critical component of our solution is identity. All the access policy in the world isn’t going to matter if at the moment we are making authorization decisions, we don’t know who (or what) is making the request.
In our example, we need to know that the ETL job and Trino queries are run by Alex and should have his access. We would also need to make similar, independent decisions for other people in our organization, even if they are leveraging shared compute clusters.
This has turned out to be a historically thorny problem. Even in a world where we were managing access policy in the compute layer (not recommended, see part I), we often struggled to enforce least-privilege access because it is difficult to have accurate user identity available for all authorization decisions.
Identity, Identity, Identity
Least-privileged access depends on knowing who or what is requesting that access. We want one consistently enforced set of policy to apply to our data, so that means we need a consistent set of identities, users, and services as part of that policy.
We need simple, consistent mechanisms for all the components in our data architecture to securely share the user identity context as part of all data access requests, all the way to the storage layer. This also requires that our notion of identity is flexible, e.g. can represent a user running an ad-hoc query as well as a scheduled ETL job.
Tabular’s Approach
Tabular enables data owners to define a single access control policy at the storage layer that is universally enforced across any access method. It directly supports applying the principle of least privilege by having flexible, robust strategies for providing user identity for every data access request.
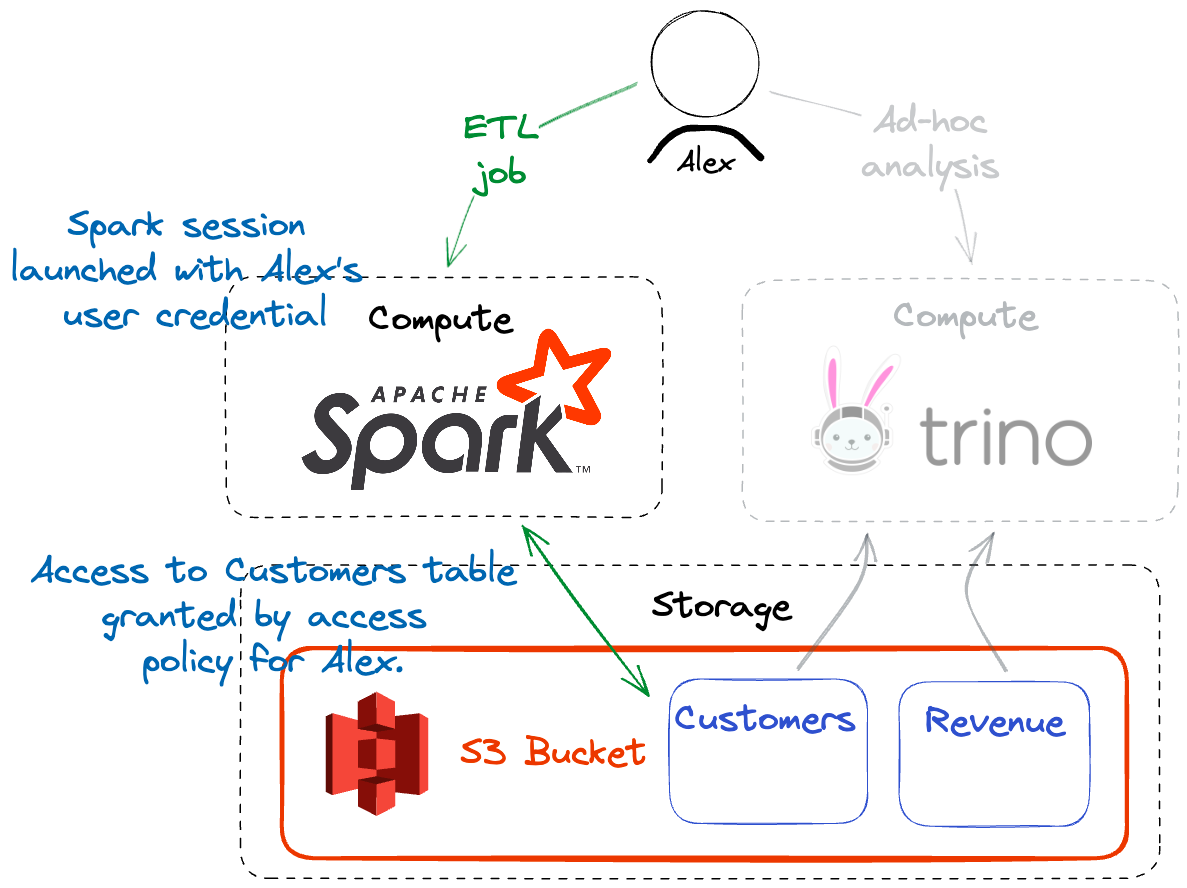
User Credential
The most straightforward way to provide identity for data access decisions is for the user to directly provide a user credential, similar to an API key. This credential can be provided as part of configuring Tabular’s Iceberg catalog in a Spark or Flink session, for example. All read and write operations performed during the session are restricted to the data access policy for the user. This could be a Spark shell on their desktop or a job submitted to a shared cluster.
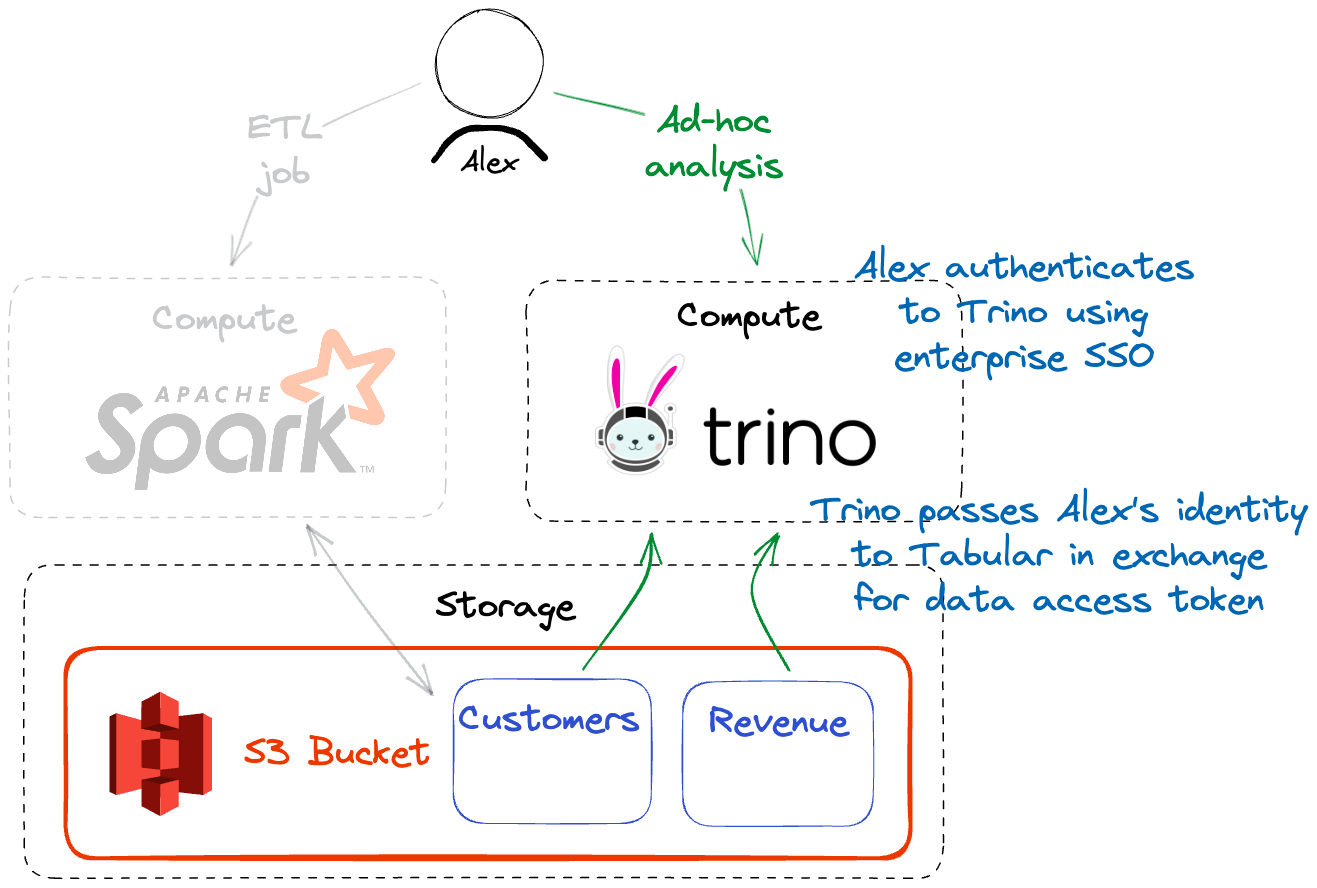
Trusted Identity Provider
In many distributed computing environments, the user is authenticated by a trusted identity provider. In those scenarios, Tabular enables that trusted infrastructure to pass the authenticated user identity along with a verification mechanism in exchange for a secure token used for data authorization decisions. This is a great option for passing identity from systems like Trino to Tabular.
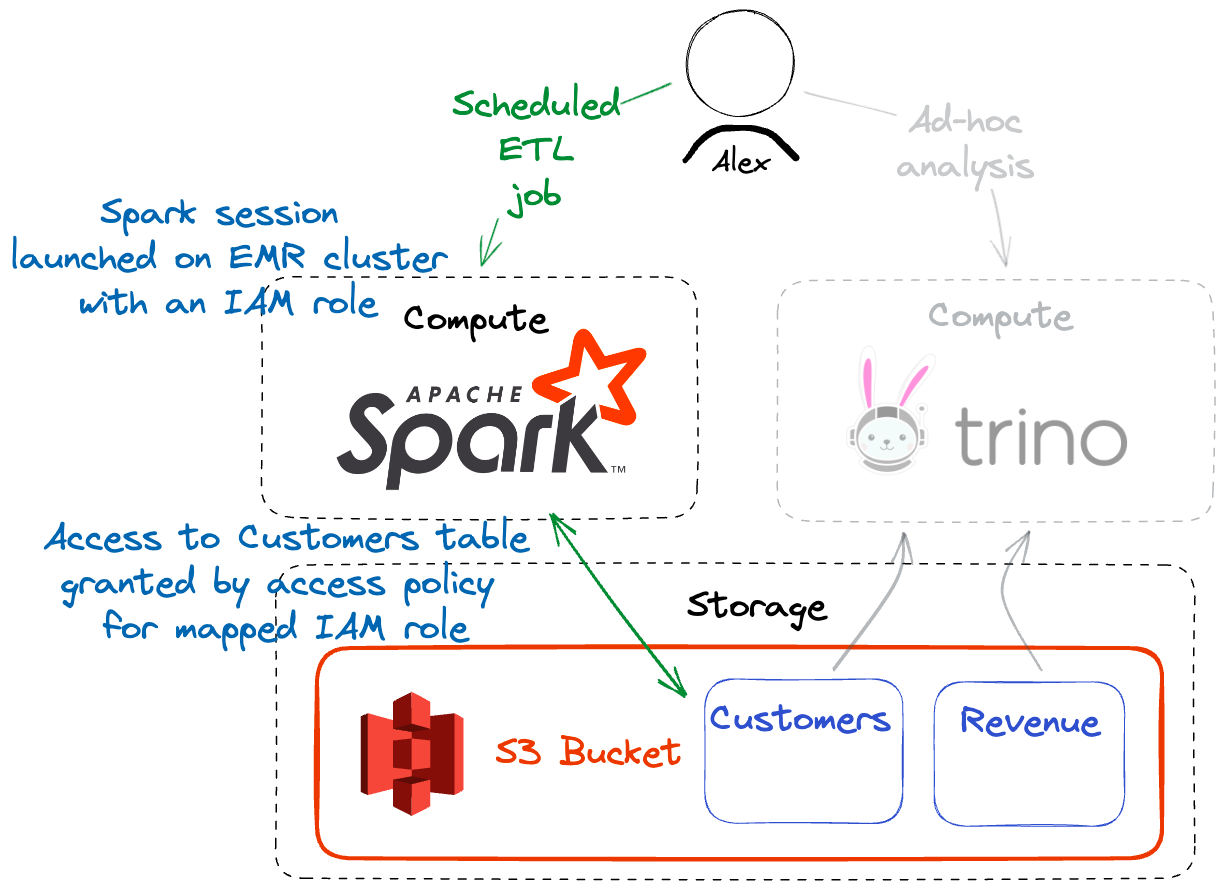
IAM Roles
For many AWS environments, it is a common best practice to grant privileges to the IAM role assigned to a particular compute instance. Tabular enables mapping IAM roles to data access roles defined in Tabular’s role-based access control system. This makes it easy to manage data access policy for scheduled jobs or processes running in AWS.
Summary
- Applying the principle of least privilege (PoLP) for data is a crucial aspect of data governance and security.
- Ensuring PoLP requires that we have the current user identity or compute instance context available for all data authorization decisions.
- Tabular provides universal data security and enables PoLP through a rich set of options for passing identity and enforcing the corresponding data access policy.
This is part II of a series of posts where we will explore the challenges and best practices around securing data in next-generation data lake architectures. There are yet more to come! Prior and succeeding posts in this series include:


