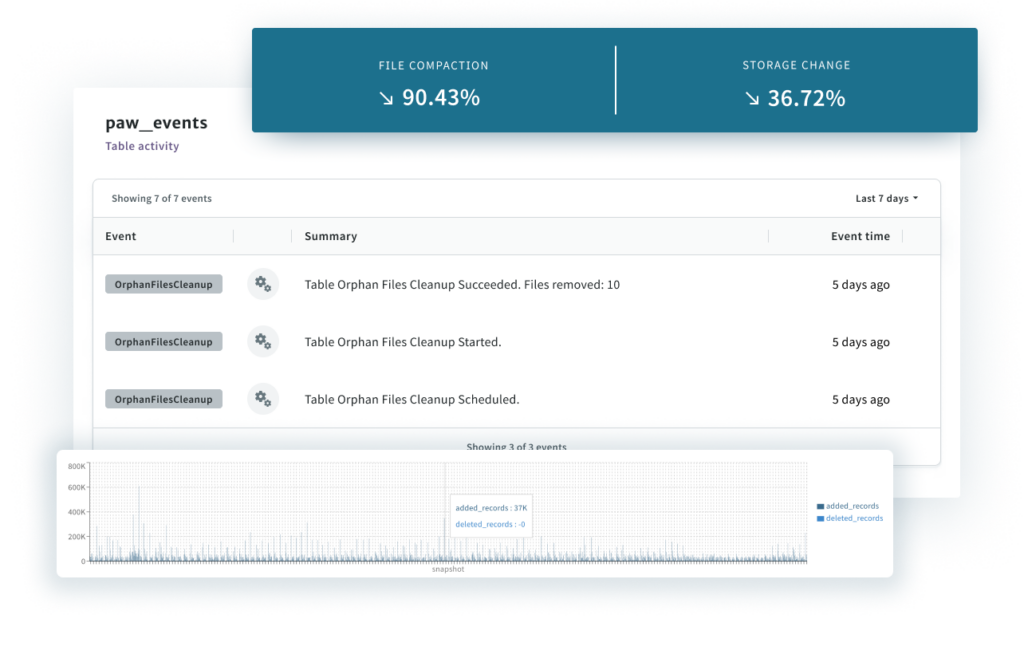
A key capability of Tabular’s platform is its optimization service, an automated capability that greatly speeds queries and reduces costs. The service monitors commits to a Tabular-managed Iceberg table and intelligently optimizes the files and storage.
We believe – based on our long experience with big data and Iceberg, and as evidenced by customer data – that we have the best optimization in the industry, achieving up to 80% reduction in storage and 2-4X query speed improvements.
Tabular optimization serves two key functions:
1) Determining what actions to take: determining what settings will optimize a given table.
2) Executing those actions at the right time: running compaction and clustering operations automatically, based on changes to the data set, changes to query patterns, or the arrival of new data.
Tabular applies optimizations upon loading new data, as well as when your jobs write to Iceberg tables. It also detects when tables need to be re-optimized, and proactively takes action to make your data smaller and your queries faster.
Since data is most likely to be queried when it is fresh, optimizing tables as new data arrives ensures more of your queries benefit from optimization. This is the main advantage of automatic “just-in-time” optimization over scheduled jobs.
Cheaper and faster queries, with no effort
Optimization substantially reduces storage and compute costs, without manual tuning by data engineers. Plus, data consumers get results to their queries faster.
- Smaller data sets mean lower storage costs and faster queries.
- Compute savings from drastically reduced files and bytes scanned
- Just-in-time optimization means new data can be efficiently queried upon arrival.
- Automatic optimization requires no additional time from your data engineers.
- Serverless operation eliminates DevOps burden.
Optimization capabilities from the original Iceberg creators
Iceberg was built to make automated, just-in-time optimization possible for large data sets. Tabular’s optimization engine is based on in-depth knowledge of and lengthy experience with real-world Iceberg deployments. Tabular profiles each table’s data and access patterns to optimize table settings for the best balance of cost and performance.
Key features of the optimization service include:
Situationally-aware optimization
- Data – We make per-table recommendations for a variety of tuning settings.
- Uses – We identify per-table query patterns to make better optimization choices
- Timing – Optimizations run when they are needed, not on a time-based schedule
- Metadata – We also maintain and optimize metadata for fast query planning
Serverless operation
- No job management, sizing and scaling
- Observability – you can build alerts and dashboards on Tabular’s metrics via the OpenMetrics API
- Commit deconfliction between Tabular’s optimization service and other writers