- Compute freedom
- Data-layer security
- Integrated ingestion
- Automated performance
- SaaS simplicity
Tabular architecture
Tabular is easy to use plus it features high-powered ingestion, performance, and RBAC under the hood.
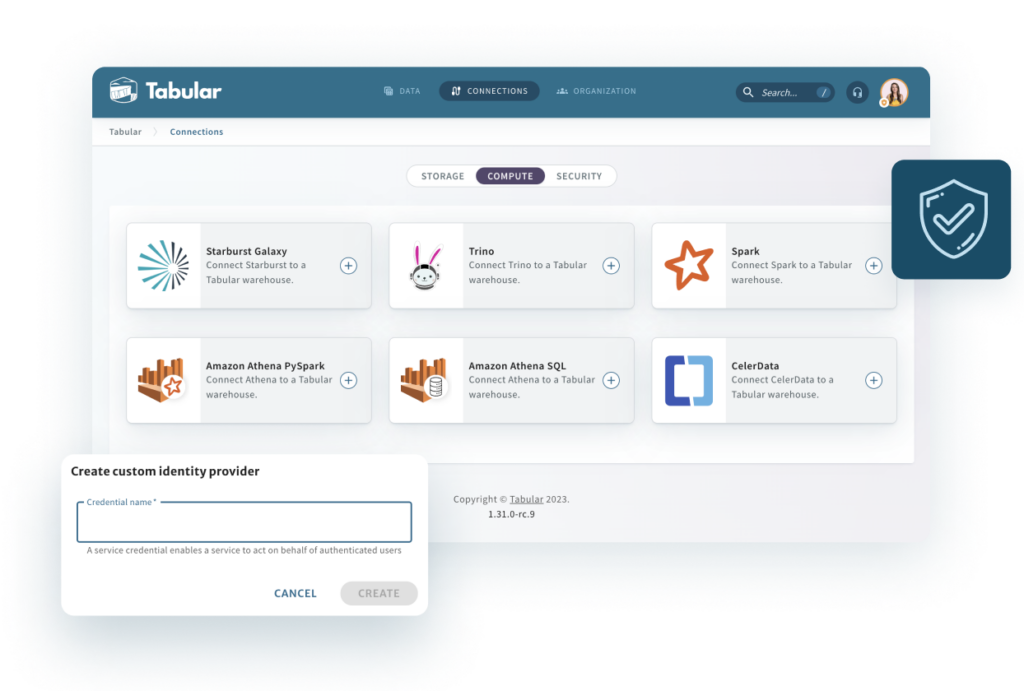
Bring your own compute
Tabular gives you the flexibility to work with multiple “best of breed” compute engines based on their strengths.
All free and paid tiers of Tabular are compatible with:
- Snowflake
- Databricks
- Athena
- Starburst
- EMR
- Spark
- BigQuery
- Trino
- Flink
- DuckDB
- PyArrow
- CelerData
- PuppyGraph
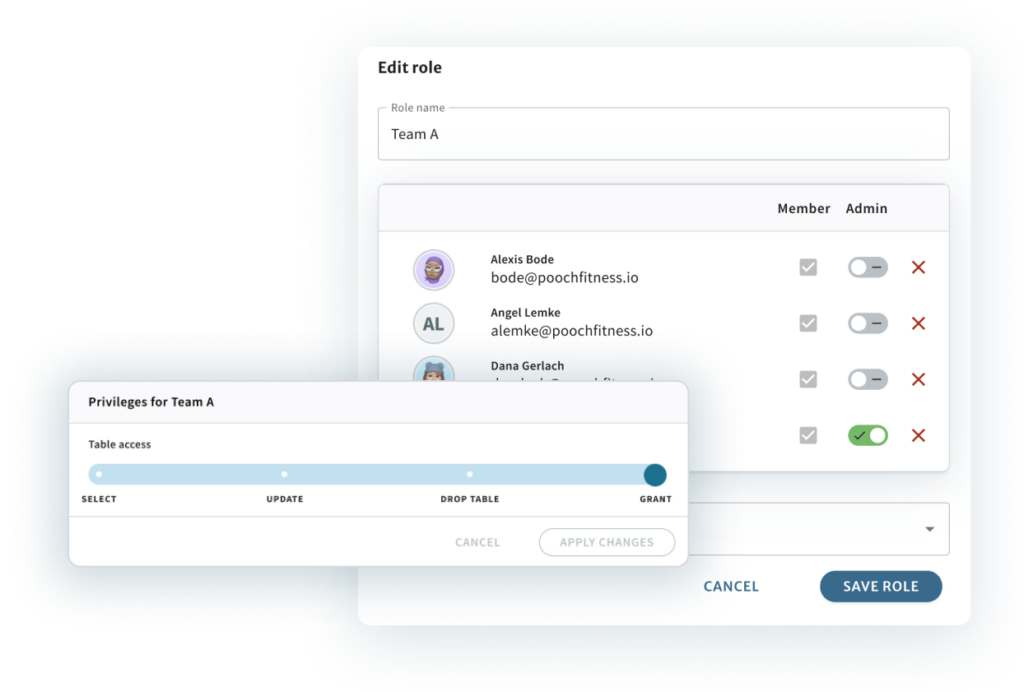
Centralized data security
Tabular secures tables in your S3 bucket using role-based access control (RBAC) policies.
- Enforce all data access from a single place.
- Assign privileges at the data warehouse database, table, or column level.
- Cascade rights down a multi-tiered roles hierarchy.
- Audit data flows and access decisions using access and change configuration logs.
- Enterprise security integrations: IAM, SSO and SCIM
- SOC 2 Type 2, HIPAA and PCI-DSS compliant
Simple, high-speed ingestion
File Loader for incremental pulls from buckets
- Micro-batches files from buckets into a Tabular table
- Supports CSV / TSV, JSON and Parquet formats
- Uses notification triggers for > 5 minute latency
- Rules to exclude files or directories
CDC for relational databases mirroring
- Load change events to mirror tables from MySQL, Postgres, or Oracle
- Near-real-time latency via micro-batching
- Configure via GUI or declarative API calls
Kafka Connect or Flink sinks for event streams
- Load raw streamed events
- Fan out to multiple tables
- Exactly once guarantees at high throughput via parallelized writes
- UPSERTs supported
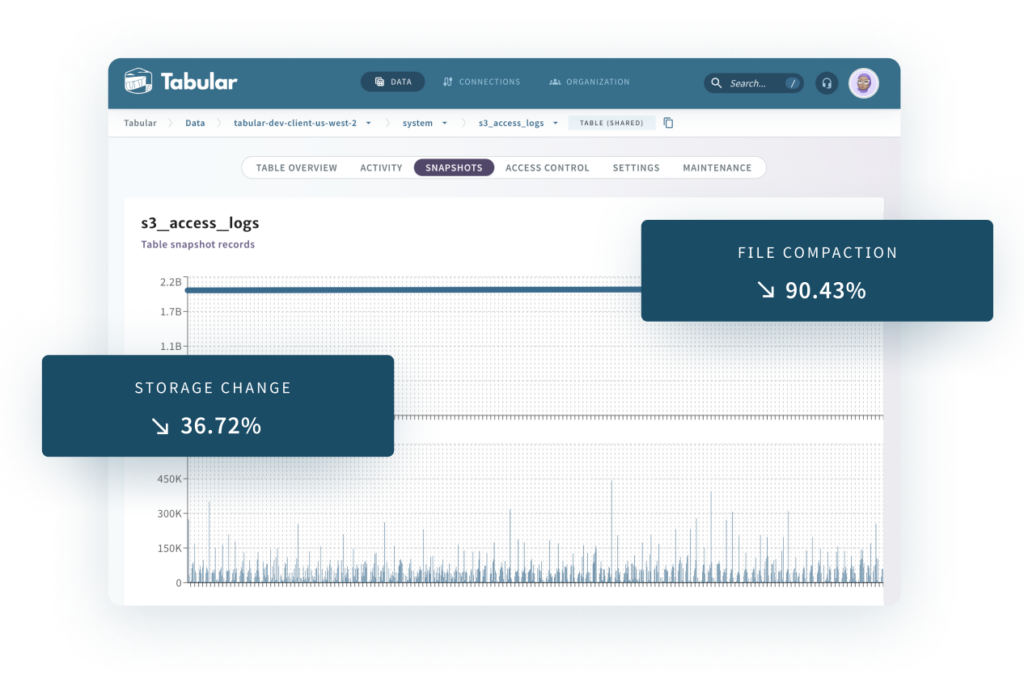
Automated performance optimization
Tabular tables are continuously optimized to speed queries and lower storage costs
- The Tabular Analyzer dynamically tunes based on the data profile and query patterns.
- Using per-table settings, Tabular clusters and compacts to maximize performance and minimize storage.
- Customers have seen total warehouse size cut by 50% with queries that run in half the time.
Painless SaaS infrastructure
Set up in minutes with the Tabular managed data catalog, access controls and data services.
- Connectors to attach query engines and storage buckets.
- Automated data retention, routine maintenance, and table health management.
- Auto-scales to fit fluctuating workloads.
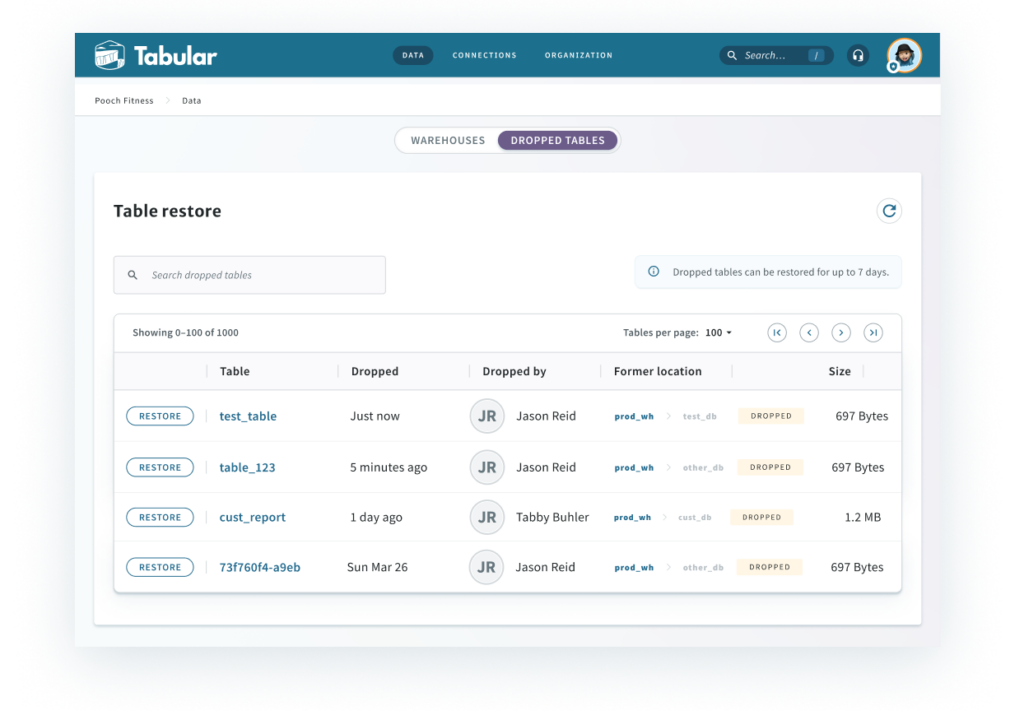
- Modern catalog features like dropped table recovery.
Tabular-managed deployment into your AWS cloud account is also available.
Tabular can help with these use cases
CDC
Ingest and merge RDBMS change events into Iceberg as they occur.
Hive Migration
Zero-downtime transition to Iceberg to improve performance, data correctness and add schema evolution.
Snowflake
Zero-copy access for Snowflake users with optimal performance.
GDPR
Architect for compliance with data layer RBAC, zero-copy storage, and fine-grained control over data “time to live”.
