
Athena, EMR, and DMS (CDC) support is now generally available
Today, just in time for AWS re:Invent, we’re launching our architecture for addressing analytics and AI on AWS using Apache Iceberg tables. Specifically the following three integrations are now general availability:
- Amazon Athena serverless query engine
- Amazon EMR big data platform, including the ability to process or query data using EMR Spark
- Change data capture (CDC) built on AWS Data Migration Service (DMS) and Debezium to sync AWS RDS databases to Iceberg tables
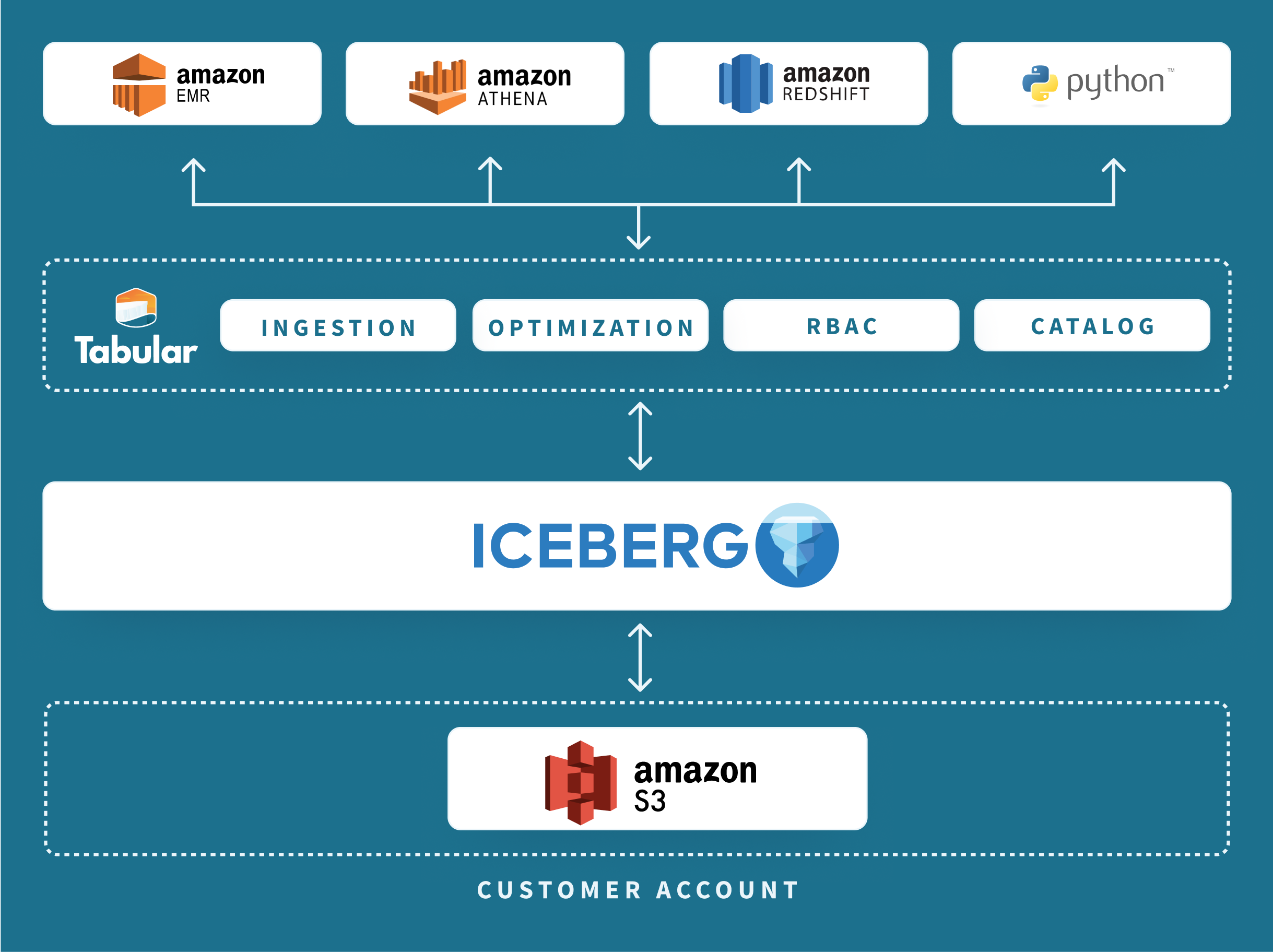
The Tabular-on-AWS architecture is a blueprint for customers who want a fast path to reinvent their S3 data lake by adding data warehouse guarantees and secure zero-copy data sharing across multiple compute services and frameworks.
Tabular-on-AWS provides a data platform that is:
- Universal — use any compute engine or framework that’s right for your team
- Secure — a single point of RBAC policy enforcement for data and metadata operations
- Zero-copy— Iceberg tables are shared, eliminating the need to copy and sync data and permissions
- Simple — as a cloud-native service, Tabular-on-AWS deployment and scaling is painless
- Efficient — automatic performance optimization makes queries 30-60% faster and cheaper.
“AWS has been a strong evangelist for Apache Iceberg, and an excellent business partner for Tabular,” said Ryan Blue, CEO and co-founder of Tabular. “We have prioritized integration with their data and analytics portfolio to ensure that AWS customers don’t have to become Iceberg experts in order to obtain its consistency, performance and data management advantages.”
“Apache Iceberg has emerged as a critical table format for customers, and the Tabular founders have been working closely with AWS since their time building Iceberg at Netflix,” said James Kirschner, General Manager of Amazon S3 at AWS, “Tabular has made it easier for AWS customers to efficiently run Iceberg at scale, by integrating Iceberg into a simple end-to-end solution encompassing AWS storage, compute, data movement, and access controls. They also help customers to automate table maintenance and storage optimization, which improves performance, lowers costs, and eliminates a time-consuming and error-prone data engineering process.”
The architecture is based on a central table store in S3 that connects seamlessly to AWS compute services, including Amazon Redshift, Athena, and EMR. Universal compatibility is provided by the Iceberg table spec and REST catalog protocol from the Iceberg community.
Tabular also addresses the data ingestion headache for AWS customers. Options for ingestion include:
- Drop files into S3 buckets and trigger incremental ingestion using Tabular File Loader
- Mirror relational databases in Iceberg tables using Tabular CDC
- Stream events using exactly-once connectors for Kafka and Kinesis.
One satisfied customer is Datto, a Kaseya company, which offers security and cloud-based software solutions to managed service providers and who has implemented Tabular to manage its Iceberg-based infrastructure on AWS.
“Tabular helped us cut our query times in half while simplifying our architecture, automating our table management and delivering near-real-time ingestion. ” said Ben Jeter, Data Architect at Datto, “Adopting Tabular on AWS has improved our customers analytics experience and has made our data team much more productive.”
You can try out the Tabular free tier. No credit card required.


