
dbt recently added Apache Iceberg support in their version 1.5 release. dbt is a popular framework for building and maintaining data pipelines. It is both a compiler and a runner:
- Compiler: dbt will compile the templated sql files based on the current state of the database.
- Runner: dbt will execute sql statements against your query engine, keeping track of dependencies, and running queries in parallel when possible.
dbt implements the best practices that are common in the software industry, such as proper documentation, version control, and testing in the data warehousing world. For example, setting up a development and production environment is easy using dbt.
This blog post will walk you through the steps on how to run a dbt pipeline against Tabular.
Installing dbt-spark
First, install dbt-spark with the session extra, to run Spark as part of dbt:
pip3 install "dbt-spark[session]" pyspark==3.4.1 --upgrade
This will install dbt-spark with Spark 3.4. Next, download the open-source Iceberg Spark runtime and the AWS bundle, and add them to the jars/ folder of Spark`:
curl https://repo1.maven.org/maven2/org/apache/iceberg/iceberg-spark-runtime-3.4_2.12/1.4.2/iceberg-spark-runtime-3.4_2.12-1.4.2.jar --output /opt/homebrew/lib/python3.11/site-packages/pyspark/jars/iceberg-spark-runtime-3.4_2.12-1.4.2.jar
curl https://repo1.maven.org/maven2/org/apache/iceberg/iceberg-aws-bundle/1.4.2/iceberg-aws-bundle-1.4.2.jar --output /opt/homebrew/lib/python3.11/site-packages/pyspark/jars/iceberg-aws-bundle-1.4.2.jar
The path can differ on your machine, you can easily look it up using pip show pyspark, and the path will show up under the Location.
Next, set up the configuration ~/.dbt/profiles.yml to point at the local Spark instance:
dbt_tabular:
outputs:
dev:
method: session
schema: dbt_tabular
type: spark
host: NA
server_side_parameters:
"spark.sql.extensions": "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions"
"spark.sql.defaultCatalog": "sandbox"
"spark.sql.catalog.sandbox": "org.apache.iceberg.spark.SparkCatalog"
"spark.sql.catalog.sandbox.catalog-impl": "org.apache.iceberg.rest.RESTCatalog"
"spark.sql.catalog.sandbox.uri": "https://api.tabular.io/ws/"
"spark.sql.catalog.sandbox.credential": "<CREDENTIAL>"
"spark.sql.catalog.sandbox.warehouse": "sandbox"
target: dev
You’ll notice the <CREDENTIAL> in the run command above. You will need to create one in the Tabular UI and paste it here. That credential unlocks a lot of access control power that is not available in Spark on its own, and we’ll cover that in a later blog.
Run the pipeline
Next we’ll clone a repository that has an example pipeline that takes data from the Taxi dataset that comes with Tabular in the examples schema.
git clone https://github.com/tabular-io/dbt-tabular.git
cd dbt-tabular
Now execute dbt run:
➜ dbt-tabular git:(main) ✗ dbt run
08:48:42 Running with dbt=1.7.1
08:48:42 Found 3 models, 3 tests, 0 snapshots, 0 analyses, 356 macros, 0 operations, 0 seed files, 0 sources, 0 exposures, 0 metrics, 0 groups
08:48:42
08:48:48 Concurrency: 1 threads (target='dev')
08:48:48
08:48:48 1 of 3 START sql table model dbt_tabular.locations ............................. [RUN]
08:48:57 1 of 3 OK created sql table model dbt_tabular.locations ........................ [OK in 8.85s]
08:48:57 2 of 3 START sql table model dbt_tabular.taxis ................................. [RUN]
08:49:27 2 of 3 OK created sql table model dbt_tabular.taxis ............................ [OK in 30.56s]
08:49:27 3 of 3 START sql table model dbt_tabular.rides ................................. [RUN]
08:49:50 3 of 3 OK created sql table model dbt_tabular.rides ............................ [OK in 22.55s]
08:49:51
08:49:51 Finished running 3 table models in 0 hours 1 minutes and 8.58 seconds (68.58s).
08:49:51
08:49:51 Completed successfully
08:49:51
08:49:51 Done. PASS=3 WARN=0 ERROR=0 SKIP=0 TOTAL=3
Open up a browser and look at your Tabular Warehouse; you’ll see the tables listed:
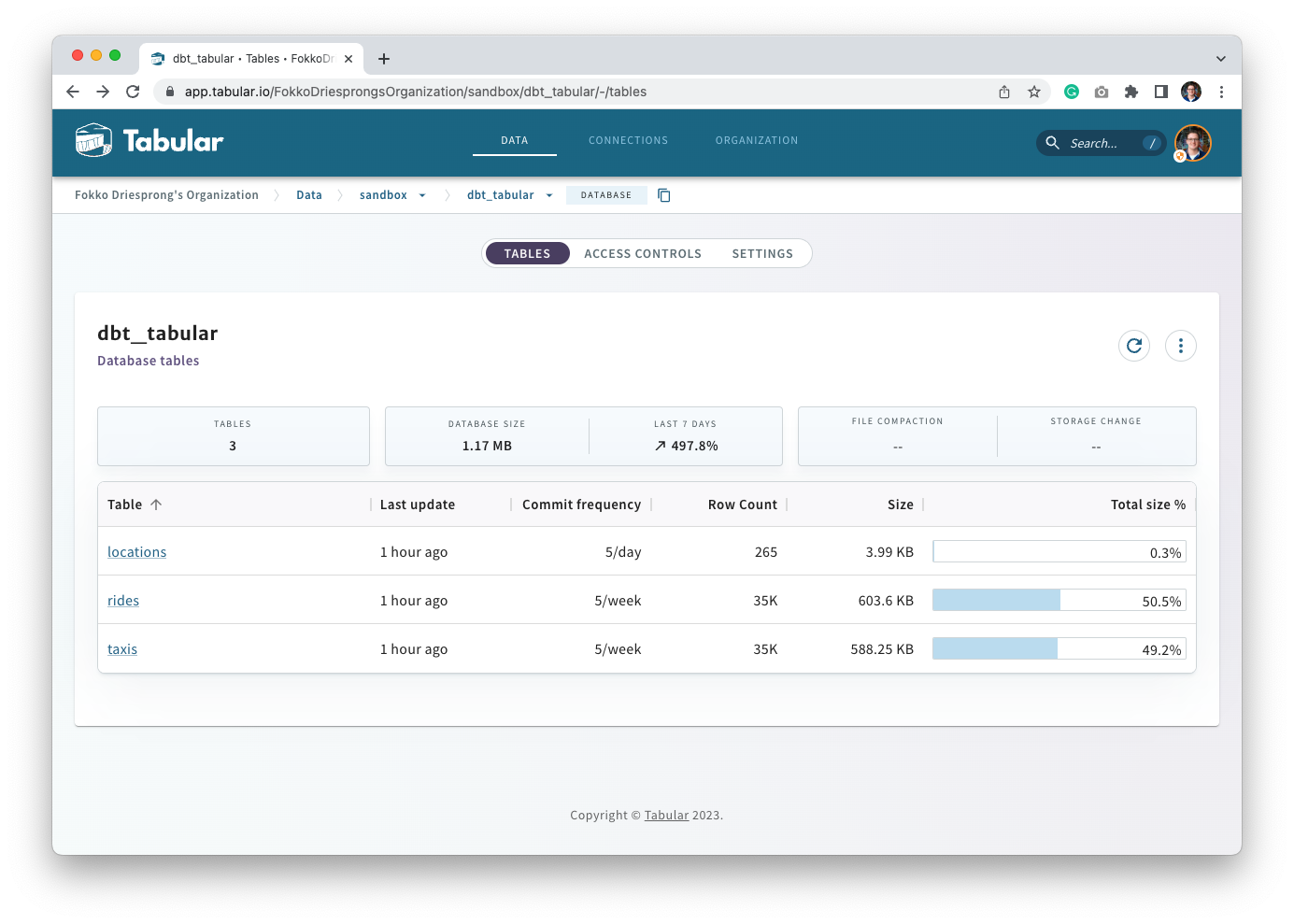
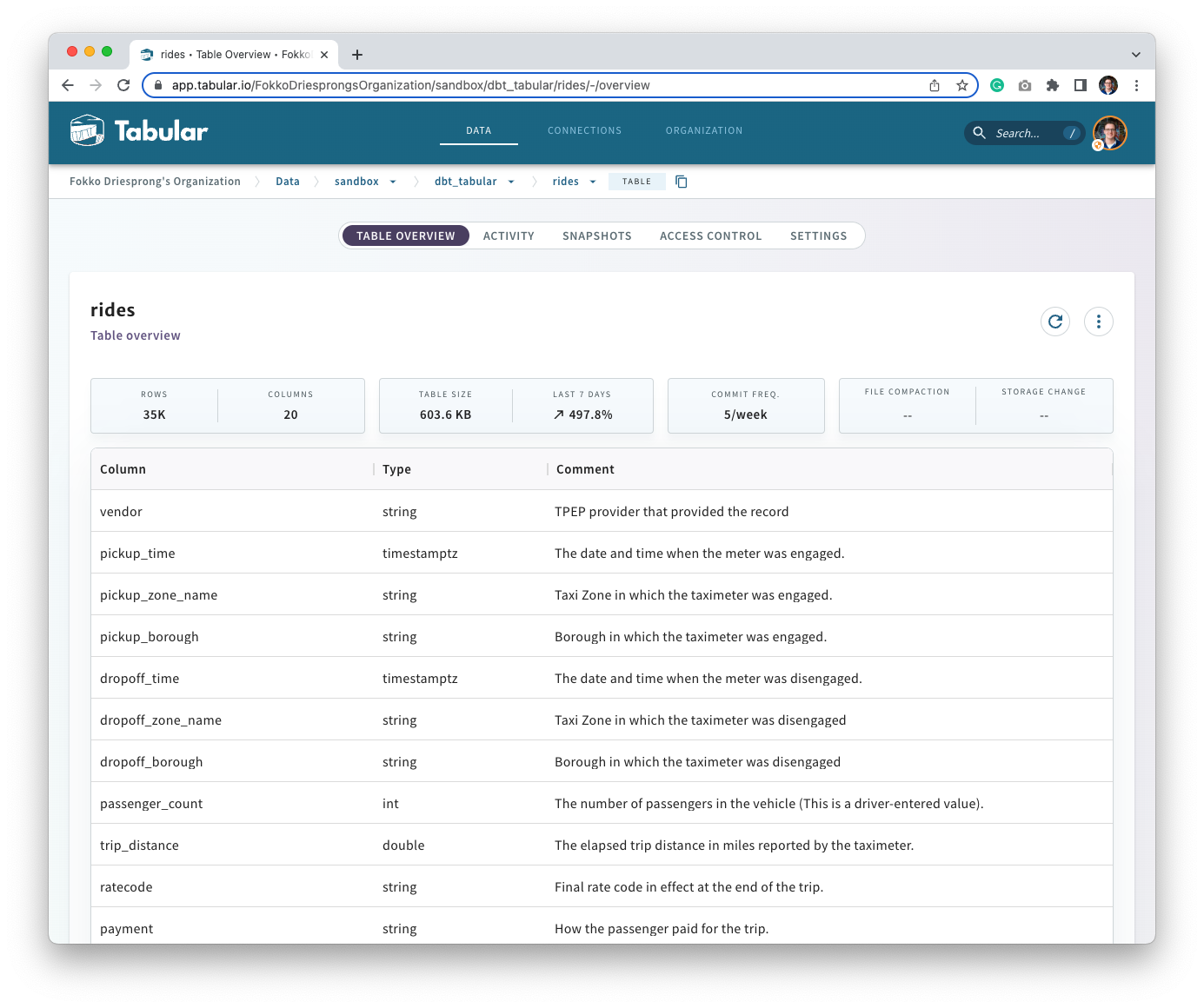
You’ll also note that all the documentation is being propagated:
On of the benefits of using Iceberg is that the table is always available:
➜ dbt-tabular git:(main) ✗ head target/run/dbt_tabular/models/consumption/rides.sql
create or replace table dbt_tabular.rides
using iceberg
As dbt functions as a compiler, all compiled sql files can be accessed from target/. Unlike when using plain parquet tables, that drop the table and then recreate it with the same name on the same location, Iceberg’s approach is to create or replace the table. This provides two benefits: firstly, the entire history is tracked within the Iceberg table, and secondly, the table remains available at all times. In contrast, the traditional method renders the table unavailable during the replacement period. With Iceberg, however, the table is always accessible, and its full history is retained.
Additionally, dbt supports incremental models, as exemplified in the locations_incremental.sql file within the repository. During the initial run, dbt detects the absence of the table and executes a simple create table statement.
create or replace table dbt_tabular.locations_incremental
using iceberg
And on the second run:
create temporary view locations_incremental__dbt_tmp as
SELECT *
FROM examples.nyc_taxi_locations;
merge into dbt_tabular.locations_incremental as DBT_INTERNAL_DEST
using locations_incremental__dbt_tmp as DBT_INTERNAL_SOURCE
on DBT_INTERNAL_SOURCE.location_id = DBT_INTERNAL_DEST.location_id
when matched then update set *
when not matched then insert *
This way, you can leverage dbt to generate the syntax for you.
Another big advantage of using Iceberg is when running tests. Because Iceberg collects metadata when the data is being written, it can determine if a column is not-null without having to go through the actual data; this also applies to not-negative checks.
➜ dbt-tabular git:(main) ✗ dbt test
11:11:33 Running with dbt=1.7.1
11:11:33 Found 4 models, 3 tests, 0 snapshots, 0 analyses, 356 macros, 1 operation, 0 seed files, 0 sources, 0 exposures, 0 metrics, 0 groups
11:11:33
11:11:36 Concurrency: 1 threads (target='dev')
11:11:36
11:11:36 1 of 3 START test not_null_rides_payment ....................................... [RUN]
11:11:39 1 of 3 PASS not_null_rides_payment ............................................. [PASS in 2.80s]
11:11:39 2 of 3 START test not_null_rides_ratecode ...................................... [RUN]
11:11:41 2 of 3 PASS not_null_rides_ratecode ............................................ [PASS in 1.96s]
11:11:41 3 of 3 START test not_null_rides_vendor ........................................ [RUN]
11:11:43 3 of 3 PASS not_null_rides_vendor .............................................. [PASS in 1.95s]
11:11:43
11:11:43 Finished running 3 tests, 1 hook in 0 hours 0 minutes and 9.93 seconds (9.93s).
11:11:43
11:11:43 Completed successfully
11:11:43
11:11:43 Done. PASS=3 WARN=0 ERROR=0 SKIP=0 TOTAL=3
Tabular and dbt
This blog not only showcases the simplicity of using dbt with Tabular managed Iceberg tables, but also highlights the exceptional speed and convenience that come with utilizing intrinsic Iceberg features.
Future work
Both Iceberg and dbt are open-source and new features are added continuously.
- Iceberg support for views. dbt relies heavily on views, and there is a lot of work being done on Iceberg views. Iceberg is query engine agnostic. In this blog the data is written using Spark, but the table can also be written to or by read any other query engine that implements the Iceberg specification. Next to the Iceberg tables, Iceberg views are coming. This will allow dbt to define views that can be queried using any Iceberg compliant engine.


