
In this blog, we’ll show you how to take the first step in Tabular, creating a table and writing data to it. You can sign up for free if you don’t already have a tabular account. You’ll also need Spark, but if you don’t have it installed, there are instructions in the connect workflow.
Getting started
If you haven’t already, download the MovieLens data and unzip it into a directory. In this example, I put it in my Data directory in ml-25m.
shawngordon@Shawns-Air ml-25m % pwd
/Users/shawngordon/Downloads/Data/ml-25m
shawngordon@Shawns-Air ml-25m % ls -la
total 2283344
drwxrwxr-x@ 9 shawngordon staff 288 Nov 21 2019 .
drwxr-xr-x@ 3 shawngordon staff 96 Mar 14 06:24 ..
-rw-rw-r--@ 1 shawngordon staff 10460 Nov 21 2019 README.txt
-rw-rw-r--@ 1 shawngordon staff 435164157 Nov 21 2019 genome-scores.csv
-rw-rw-r--@ 1 shawngordon staff 18103 Nov 21 2019 genome-tags.csv
-rw-rw-r--@ 1 shawngordon staff 1368578 Nov 21 2019 links.csv
-rw-rw-r--@ 1 shawngordon staff 3038099 Nov 21 2019 movies.csv
-rw-rw-r--@ 1 shawngordon staff 678260987 Nov 21 2019 ratings.csv
-rw-rw-r--@ 1 shawngordon staff 38810332 Nov 21 2019 tags.csv
shawngordon@Shawns-Air ml-25m %
Click on the “Connect Apache Spark…” menu item to get set up in a Spark environment. We will then work with the included default database as seen below:
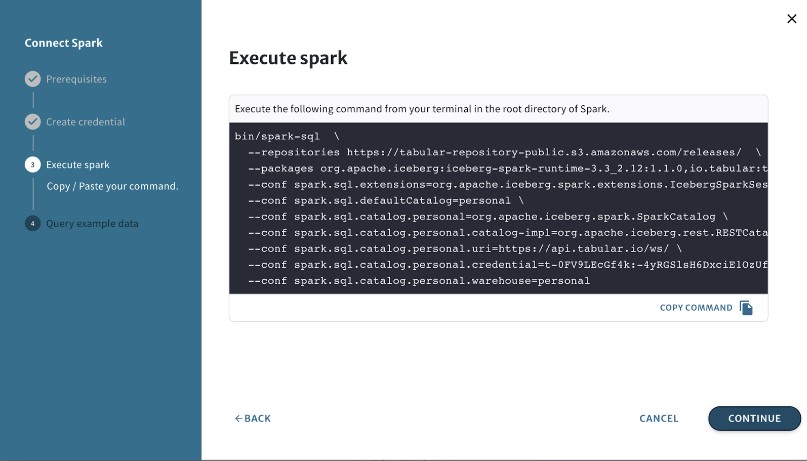
In a terminal window, we’re going to launch Spark and paste the command we just copied.
bin/spark-sql \
--repositories https://tabular-repository-public.s3.amazonaws.com/releases/ \
--packages org.apache.iceberg:iceberg-spark-runtime-3.3_2.12:1.1.0,io.tabular:tabular-client-runtime:1.2.6 \
--conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions \
--conf spark.sql.defaultCatalog=personal \
--conf spark.sql.catalog.personal=org.apache.iceberg.spark.SparkCatalog \
--conf spark.sql.catalog.personal.catalog-impl=org.apache.iceberg.rest.RESTCatalog \
--conf spark.sql.catalog.personal.uri=https://api.tabular.io/ws/ \
--conf spark.sql.catalog.personal.credential=<tabular credential> \
--conf spark.sql.catalog.personal.warehouse=personal
Working with the data
We will start by creating a temporary view on top of the movies.csv file so that we can load it into our Iceberg table. Modify path to match the location of your data files.
CREATE TEMPORARY VIEW movies (
movieId bigint,
title string,
genres string)
USING csv
OPTIONS (
path '/Users/shawngordon/Downloads/Data/ml-25m/movies.csv',
header true
);
Create and load the Iceberg table by selecting all of the data from the movies view
CREATE TABLE default.movies AS SELECT * from movies;
Oops, we wanted to follow snake case for our column names to accommodate engines like Hive, but we used the column header from the CSV file, namely movieId, so we want to change it. Iceberg makes schema evolution easy; we just issue the command:
ALTER TABLE default.movies RENAME COLUMN movieId to movie_id;
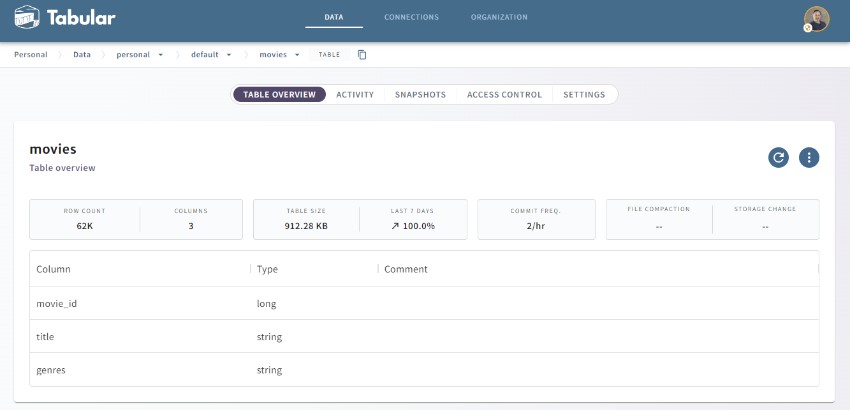
Back in Tabular, we can see the table has been created and includes our updated column names:
Let’s do a quick SELECT statement here to see the results:
spark-sql> select * from movies limit 10;
1 Toy Story (1995) Adventure|Animation|Children|Comedy|Fantasy
2 Jumanji (1995) Adventure|Children|Fantasy
3 Grumpier Old Men (1995) Comedy|Romance
4 Waiting to Exhale (1995) Comedy|Drama|Romance
5 Father of the Bride Part II (1995) Comedy
6 Heat (1995) Action|Crime|Thriller
7 Sabrina (1995) Comedy|Romance
8 Tom and Huck (1995) Adventure|Children
9 Sudden Death (1995) Action
10 GoldenEye (1995) Action|Adventure|Thriller
Time taken: 0.596 seconds, Fetched 10 row(s)
Now we will load the ratings.csv file. This one has a bit of a trick as we want to cast the timestamp field into a human-readable date in our table. It is stored in the CSV as a string in epoch format:
CREATE TEMPORARY VIEW ratings (
userId bigint,
movieId bigint,
rating float,
timestamp bigint)
USING csv
OPTIONS (
path '/Users/shawngordon/Downloads/Data/ml-25m/ratings.csv',
header true
);
CREATE TABLE default.ratings AS
SELECT
userId as user_id,
movieId as movie_id,
rating,
from_unixtime(ratings.timestamp) as rated_at
FROM ratings
PARTITIONED BY rated_at;
For our final query, we’ll join the movies and ratings tables to look at the top 10 movies that had over 100 ratings:
SELECT
m.movie_id,
title,
avg(rating) as avg_rating,
count(1) as rating_count
FROM movies m
JOIN ratings r ON
m.movie_id = r.movie_id
GROUP BY m.movie_id, title
HAVING rating_count > 100
ORDER BY avg_rating DESC
LIMIT 10;
171011 Planet Earth II (2016) 4.483096085409253 1124
159817 Planet Earth (2006) 4.464796794504865 1747
318 Shawshank Redemption, The (1994) 4.413576004516335 81482
170705 Band of Brothers (2001) 4.398598820058997 1356
171495 Cosmos 4.3267148014440435 277
858 Godfather, The (1972) 4.324336165187245 52498
179135 Blue Planet II (2017) 4.289833080424886 659
50 Usual Suspects, The (1995) 4.284353213163313 55366
198185 Twin Peaks (1989) 4.267361111111111 288
1221 Godfather: Part II, The (1974) 4.2617585117585115 34188
Time taken: 18.718 seconds, Fetched 10 row(s)
Securing the data
We’ve created some tables, loaded data and done some table manipulation, but what about data security? As any Spark user knows, data security is not really a thing with Spark, but Tabular provides you with granular control. By navigating to the Access controls tab, we can look at the privileges that Tabular grants to the table by default:
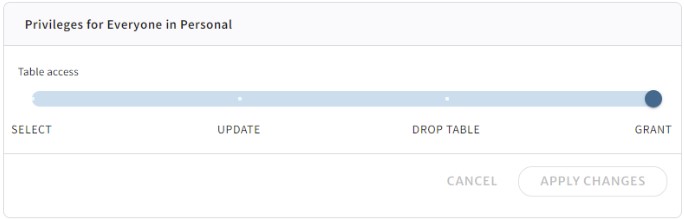
If we want to limit actions for this role only to allow read access, then we just drag the slider all the way to the left and apply the change:
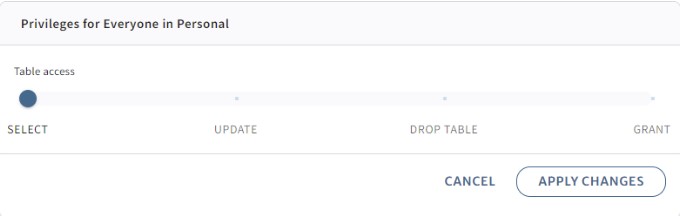
Now let’s try:
INSERT INTO default.movies VALUES (0, 'Shawn\'s Home Videos', 'Horror');
And look what happens, we get an error from Spark that Tabular has blocked the operation:

Summary
In just a few steps, you were able to create and load tables in Tabular using Spark and then perform various queries on the data. We also looked at how you can lock down your data in ways that have previously not been available. Now that you have an environment loaded try out different roles, permissions, and credentials to see what is possible. This brief introduction illustrated some Tabular concepts and how quickly you can get started. Our documentation includes many other examples and tips, as does our YouTube channel.


