
Over the past few months, we’ve been asked a lot of questions about Iceberg FileIO like “does it support Azure or Google Cloud?” or “why not use S3AFileSystem from Hadoop?”. Based on those conversations, there appears to be a fair amount of confusion around what FileIO is and what role it plays with various storage providers and processing engines. This is a great opportunity to dive a little deeper into the internal design of Iceberg and clarify how it differs from legacy approaches to interfacing with the storage layer.
- What is FileIO?
- Why do we need FileIO?
- File Systems in Distributed Processing
- Dataset Layout and Task Planning
- Committing Data
- Cloud Native I/O Architecture
- FileIO in Practice – Processing Engines
- FileIO Implementations
What is FileIO?
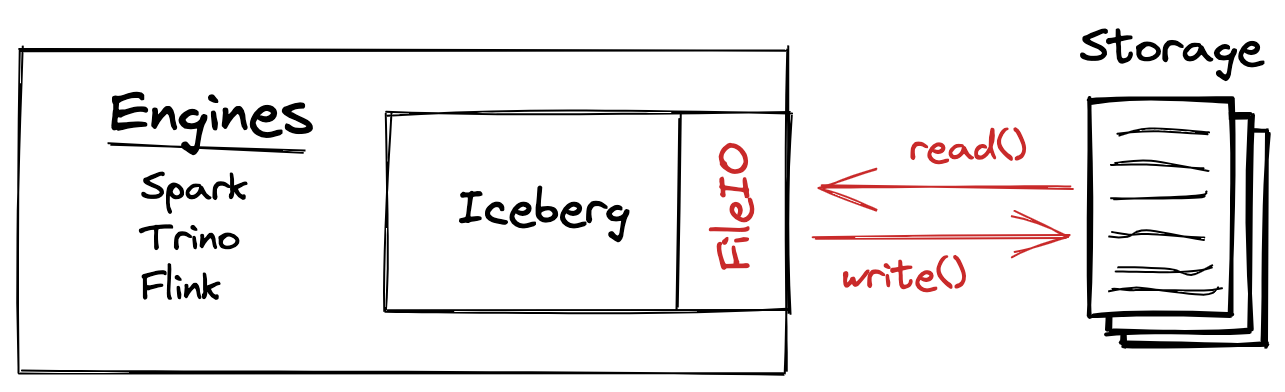
FileIO is the primary interface between the core Iceberg library and underlying storage. I frequently say that it is just two operations: open for read and open for write. That is oversimplified but captures how straightforward the interface is. Iceberg makes this possible because it has a fundamentally different architecture from legacy approaches to managing data.
Why do we need FileIO?
Distributed processing has advanced from an engineering challenge to the foundation for whole data platforms and ecosystems over the last decade. In parallel came the transition from the data center and self-managed distributed storage in systems like HDFS to cloud based storage like AWS S3. These shifts exposed the shortcomings of the legacy pairing of storage and compute contracts.
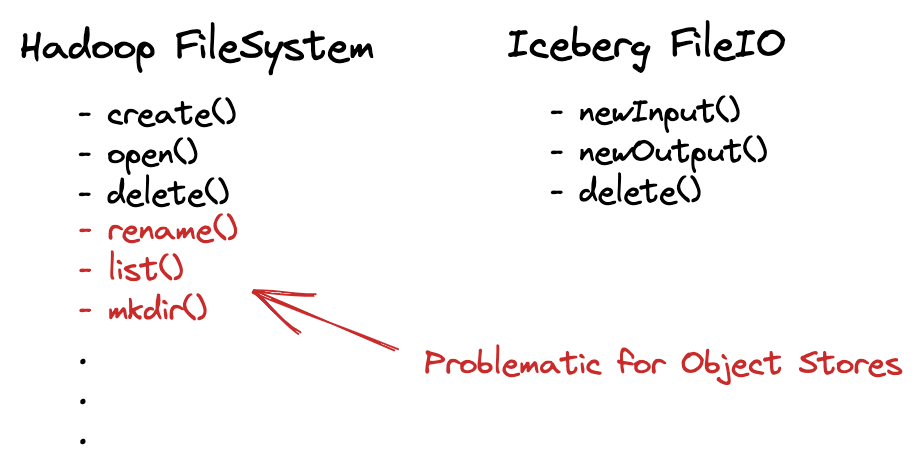
Operations in the cloud (like listing) are expensive, slow, and in some cases inconsistent depending on the guarantees of the storage provider. This is compounded by the traditional hierarchical pathing and partition structures being the inverse of optimal layouts for the key space in systems like S3. While object stores can handle immense amounts of data and requests, legacy approaches to data management strain many systems to the point of failure (at least from the client perspective).
File system directories also cause problems in that the layout mutates as compute occurs. When a job is committing data, rename operations are not atomic as a set. In the cloud, some implementations of rename are not atomic at all and split into two operations: copy and delete. This means there is no real isolation between readers and writers of data. While it might be possible to avoid conflicts by carefully scheduling workflows to avoid collisions/inconsistency, it is error prone and fails to address the ever increasing parallel workloads and ad hoc analytics needs.
File Systems in Distributed Processing
In order to understand how Iceberg addresses numerous challenges that exist in many distributed processing systems, it helps to recognize that distributed storage and processing evolved together. This close relationship naturally resulted in leveraging the storage layer to solve a series of problems that presented in the processing space. We’ll take a look at two such examples.
Dataset Layout and Task Planning
The first case is related to how data has traditionally been organized; by directories. This makes sense in the context of building storage and processing together. Early data collection was often rather messy and inconsistent while processing was handcrafted code compiled directly against the MapReduce APIs. This put a lot of responsibility on job authors to parse and understand the data as it existed in the storage layer (hence path based addressing and schema-on-read). Different datasets were placed under different paths and hierarchies where contextual data in the path was commonly used as physical partitioning to reduce how much data would be read by a single job. Datasets in this model are defined by the physical file layout and processing data relies on listing directories to discover the input files for a job.

As the processing space evolved, layers were added on top of the file system to further abstract this complexity. The Hive metastore brought a logical abstraction allowing datasets to be referenced by name, but did not address the physical pathing and partitioning (pathing is still surfaced explicitly as columns in a table schema). The file system remained an essential component and played the same central role.
Committing Data
The second case is related to how distributed processing jobs produce data and the role the file system plays in that process. For processing to be both distributed and reliable, two properties are required: execution needs to be broken down into tasks that process data in parallel and each task must be idempotent to support retries and speculative execution. Again, the file system comes into play in that each task attempt writes a file and leverages a conditional rename in the file system layer to deconflict competing writes.

In both of these cases, the file system plays a critical role in terms of defining the dataset and providing locking mechanisms for concurrency and conflict resolution. In the context of processing a large amount of data in isolation, these mechanisms work to an extent and have underpinned distributed processing for over a decade. Unfortunately, these mechanisms break down as distributed processing requirements grow in scale/complexity, are adapted to new ecosystems (e.g. cloud-based infrastructure), and have more stringent requirements around data integrity.
Cloud Native I/O Architecture
A primary focus in the design of Iceberg was addressing the issues caused by treating datasets and file structures interchangeably. Our experience building cloud based data processing infrastructure made us acutely aware of the challenges previously enumerated and Iceberg was an opportunity to fundamentally rethink the interface to storage that underpins tables.

The reason Iceberg can leverage a simple interface like FileIO, is that all locations are explicit, immutable, and absolute in the metadata structure. Rather than referencing directories, Iceberg tracks the full state of the table all the way to the file level. So from the very top of the metadata hierarchy, you can reach any location without requiring a listing operation. Similarly, a commit is adding a new branch to the metadata tree that is fully reachable and requires no rename operations.
Tracking data at the file level also allows Iceberg to completely abstract the physical layout. Partition information is stored in the metadata at a file level, so the physical location is completely independent of the logical structure. This separation allows for hidden partitioning via transforms on the underlying data.
FileIO in Practice
Processing Engines
We’ve discussed why the FileIO API exists and the problems it addresses, but there is some nuance to how it is applied and adapted to existing implementations. In order to understand where and how FileIO is leveraged, we’ll separate usage into two different categories: metadata operations and data operations.
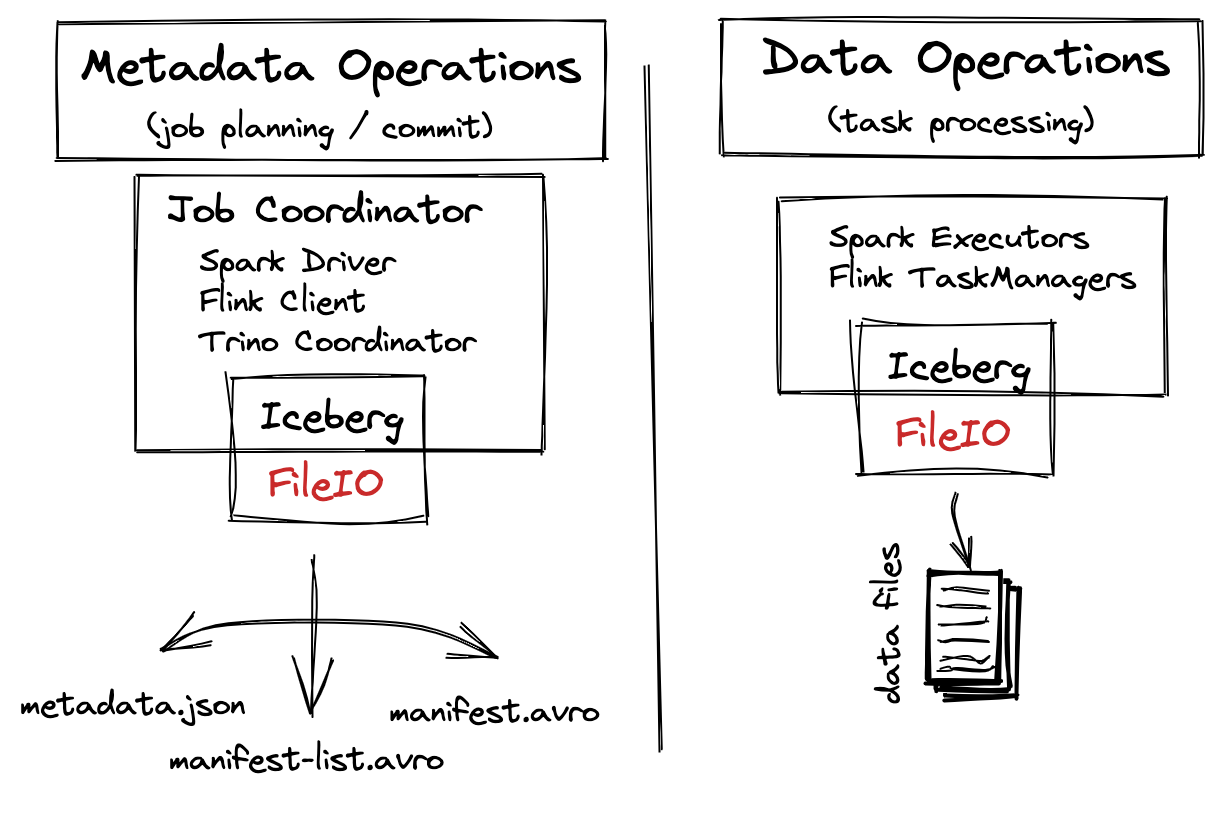
Metadata operations are performed during planning and commit phases where files like the metadata file, manifest list, and manifests are read and written. In the Iceberg library, these operations are carried out entirely through the FileIO API. There are some cases where these files are read by workers (e.g. distributed processing of metadata tables), but to simplify, we will ignore those for now as all metadata flows through the FileIO path.
Data operations relate to where processing engines read and write data during task processing. Tasks use the FileIO interface to read and write the underlying data files. The locations of these files are then gathered and added to the table metadata during the commit process. It is worth noting that not all read/write operations are required to go through this path, so engines can customize how they interact with data. Ultimately, read locations are provided by the core Iceberg library and output locations are collected for committing back to the table.
FileIO Implementations
Iceberg also has multiple FileIO implementations, but broadly these can be broken down into two categories as well: HadoopFileIO and native FileIO implementations.
HadoopFileIO provides an adapter layer between any existing Hadoop FileSystem implementation (HDFS, S3, GCS, etc.) and Iceberg’s FileIO API. This means that any storage system that has a Hadoop FileSystem implementation can be used with Iceberg.
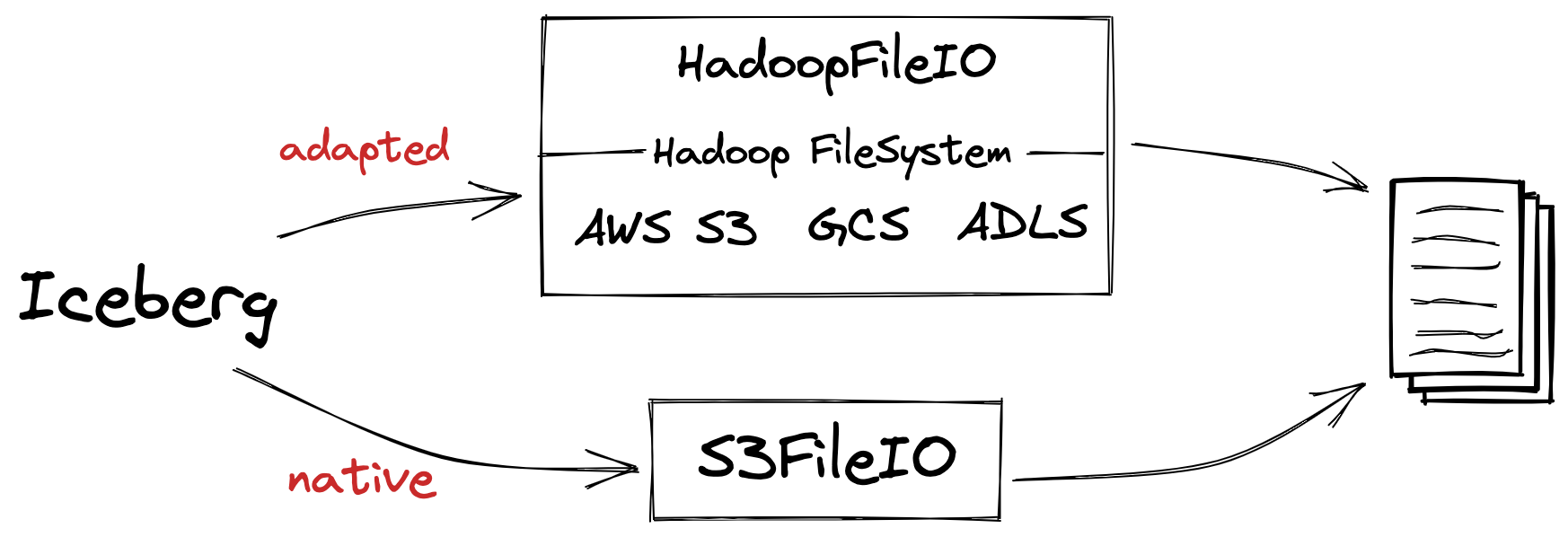
It is also possible to provide native Implementations like S3FileIO. But why have a native S3 implementation if S3AFileSystem can be easily adapted? There are a number of advantages:
Contract Behavior: Hadoop FileSystem implementations have strict contract behavior resulting in additional requests (existence checks, deconflict directories and paths, etc.) which add overhead and complexity. Iceberg uses fully addressable and unique paths which avoids additional complexity.
Optimized Uploads: S3FileIO optimizes for storage/memory by progressively uploading data to minimize disk consumption for large tasks and preserves low memory consumption when multiple files are open for output.
S3 Client Customization: the client uses the latest major AWS SDK version (v2) and allows for users to fully customize the client for use with S3 (including any S3 API compatible endpoint).
Serialization Performance: Task processing with HadoopFileIO requires serialization of the Hadoop Configuration, which is quite large and in degenerate cases can slow down processing and result in more overhead than data
processed.
Reduced Dependencies: Hadoop FileSystem implementations introduce a large dependency tree and a simplified implementation reduces overall packaging complexity.
These are just some of the examples stemming from the S3 implementation, but recent additions of the GCSFileIO (Google Cloud) and OSSFileIO (Aliyun) allow for similar enhancements. So while there is an easy path to supporting any Hadoop compatible storage layer, FileIO provides a path to store data in any system that can provide basic read/write operations without requiring full file system semantics.
Iceberg FileIO is the Future
FileIO may seem like a really simple concept given the limited scope of the interface. However, what it represents is a fundamentally different way of thinking about the interaction between engines and table formats. Iceberg’s
architecture opens a path forward that eliminates many of the legacy conventions that result in workarounds at the storage interface and brings the focus more directly on the table interface and contracts necessary to provide guarantees at the data set level and above.


