
When people first hear about Iceberg, it’s often difficult to understand just what a table format does. Table formats are a relatively new concept in the big data space because previously we only had one: Hive tables. I’ve found that the easiest way to think about it is to compare table formats to file formats. A table format tracks data files just like a file format tracks rows. And like a file format, the organization and metadata in a table format helps engines to quickly find the data for a query and skip the rest.
There is more to a table format than just finding or skipping data—reliable, atomic commits are another critical piece for a future post. This post will focus on how Iceberg’s metadata forms an index that Iceberg uses to scale to hundreds of petabytes in a single table and to quickly find matching data, even on a single node.
To demonstrate metadata indexing, I’ll use an example table of events that is written by Flink from a Kafka stream. This events table is organized into daily partitions of event time and bucketed by the device ID that sent an event.
CREATE TABLE events (event_time timestamptz, device_id bigint, ...)
PARTITIONED BY (days(event_time), bucket(device_id, 64))
The purpose of this table is to debug problems by looking up events for a particular device during a particular time window with queries like this one:
SELECT * FROM events WHERE device_id = 74 AND
event_time > '2021-10-01T10:00:00' AND
event_time < '2021-10-04T20:00:00'Metadata from the bottom up
Iceberg stores data in Parquet, Avro, or ORC files. File formats like Parquet already make it possible to read a subset of columns and skip rows within each data file, so the purpose of table-level metadata is to efficiently select which files to read. Iceberg tracks each data file in a table, along with two main pieces of information: its partition and column-level metrics.
Partitions in Iceberg are the same idea as in Hive, but Iceberg tracks individual files and the partition each file belongs to instead of keeping track of partitions and locating files by listing directories. The partition of a file is stored as a struct of metadata values that are automatically derived using the table’s partition transforms. Storing the values directly instead of as a string key makes it easy to run partition filters to select data files, without needing to parse a key or URL encode values like in Hive.
For our example table, a row with event_time=2021-10-01 11:23:31.129055 and device_id=74 is stored in a Parquet file under partition (2021-10-01, 1), corresponding to the partition transforms, days(event_time) and bucket(device_id, 64).
Partitions tend to be fairly large, with tens or hundreds of files in each partition. Iceberg stores column-level metrics for each data file for an extra level of filtering within each partition. The metrics kept are lower and upper bounds, as well as null, NaN, and total counts for the columns in a file. After filtering by partition, Iceberg will check whether each file matches a given query filter using these stats. File formats will also use column stats to skip rows, but it is much more efficient to keep stats in table metadata to avoid even creating a task for a file with no matching rows.
In the events table, looking for an hour-sized range of event_time would require reading a whole day if filtering with only day-sized partitions. However, if data is being committed continuously from Kafka, each data file would have a small slice of event_time. Iceberg will compare the query’s time range with each file’s event_time range to find just the files that overlap, which can easily be a 10-100x reduction in data.
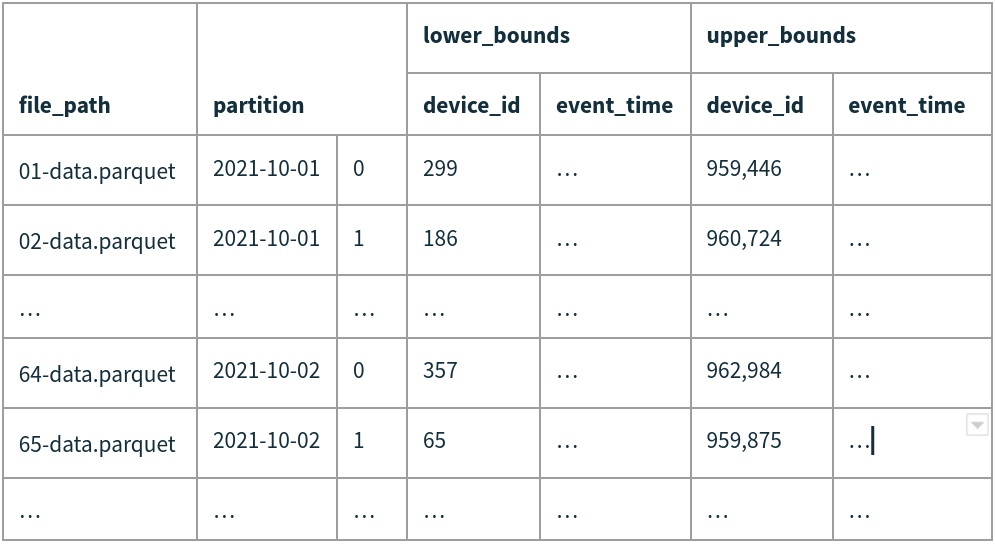
Iceberg keeps the partition and column metrics for data files in manifest files. Each manifest tracks a subset of the files in a table to reduce write amplification and to allow parallel metadata operations. One of the most important reasons to split metadata across files is to be able to skip whole manifests and not just individual files. Just like Iceberg uses value ranges for columns to skip data files, it also uses value ranges for partition fields to skip manifest files (along with whether there are null or NaN values).
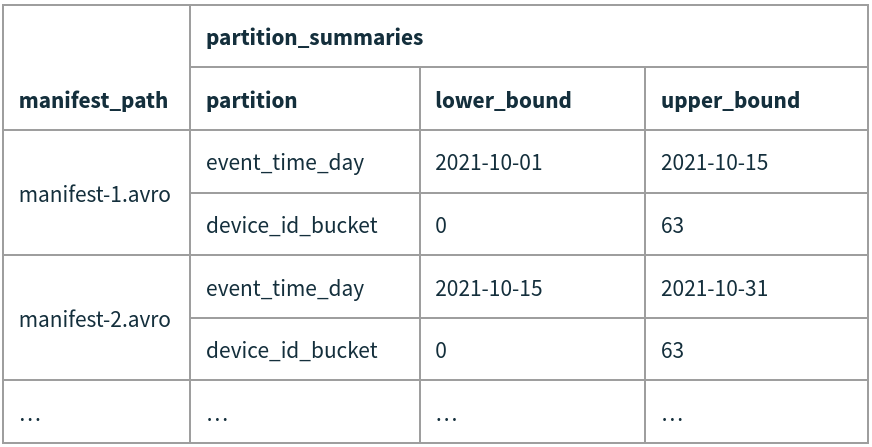
The metadata for every manifest in a given version or snapshot is kept in a manifest list file. When reading manifests from the list, Iceberg will compare a query’s partition predicates with the range of values for each partition field and skip any manifest that doesn’t overlap. This additional level of indexing makes a huge difference in the amount of work needed to find the files for a query. When tables grow to tens or hundreds of petabytes there can be gigabytes of metadata and a brute force scan through that metadata would require a long wait or a parallel job—instead, Iceberg skips most of it.
Putting it all together
Let’s go through an example of what happens when Iceberg plans the event query from above:
SELECT * FROM events WHERE device_id = 74 AND
event_time > '2021-10-01T10:00:00' AND
event_time < '2021-10-04T20:00:00'
First, Iceberg will convert the row filter into a partition filter, which produces:
device_id_bucket = 1 AND
event_time_day >= '2021-10-01' AND
event_time_day <= '2021-10-04'After selecting the snapshot to read, Iceberg will open that snapshot’s manifest list file and find all of the manifests that may contain matching data files. In this example, each data file contains all 64 device ID buckets, so the predicate on device_id_bucket doesn’t help. The manifests, however, have useful ranges of dates and only manifest-1.avro overlaps. Iceberg will simply skip manifest-2.avro.
Next, Iceberg will read the set of manifests in parallel and apply the partition filter to the partition tuple for each data file. This first step will eliminate all of the files where the date or bucket ID don’t match. Even though the device_id_bucket filter wasn’t helpful when filtering manifests, for data files it eliminates all but 1 in 64. Just 02-data.parquet and 65-data.parquet remain.
After testing a data file’s partition tuple, Iceberg moves on to test column ranges. This final filter step removes file 02-data.parquet because its range of device_ids doesn’t include the target ID, 74.
What about the real world?
Filtering down to just one file in an example is great, but you may wonder: is this representative of the real world? Yes! In fact, this post is based on a real-world use case where Iceberg and Trino (then called PrestoSQL) were used to replace an expensive in-memory database cluster.
But, there are a couple of differences to keep in mind.
The example above used a small device_id value that happened to be outside the lower bounds of a file, even though the file’s range was basically 0 to 1,000,000. But column range filtering is most effective when data is clustered so that files contain smaller ranges, like 0 to 100,000 or 200,000 to 300,000. To cluster data, use a global sort by the partition columns and other filter columns. This will prep the files so that Iceberg can skip more data than in the example.
Another difference between this example and real world cases is data file grouping. When writing manifest files, Iceberg will keep data files that are committed to the table around the same time together in manifests. That leads to a grouping very similar to the example for data flowing in through streaming writers and time-based ETL jobs. As long as your read pattern and your write pattern are aligned, keeping files written around the same time near one another in metadata keeps job planning time low.
But, there are situations where the write-time grouping doesn’t work well. Late-arriving data can cause newer manifests to overlap with older time ranges, increasing work for query planning. Partition and column filters still filter out the files, but planning takes longer and that leads to longer query wall-time.
To fix this, Iceberg has helpers that re-group data files in manifest files. This can be as easy as calling a stored procedure: CALL system.rewrite_manifests("db.events") or as complicated as providing functions to select the manifests to rewrite and how to group data files.
Summary
File formats, like Parquet, track metadata about rows and columns so that they can quickly skip rows and columns that aren’t needed. Table formats play a similar role by keeping metadata to filter out unnecessary data files. Iceberg is uniquely good at this because it indexes both data and its own metadata. Iceberg can scale from a single node all the way up to a massive parallel query—by keeping the right amount of metadata for each data file and efficiently skipping large portions of its own metadata while planning.


