GETTING STARTED
Amazon EMR is an easy way to deploy distributed data processing frameworks like Apache Spark, Apache Flink, Apache Hive, and Trino. In this recipe, you will connect an EMR cluster running Spark to multiple Iceberg catalogs.
Using EMR with Iceberg tables
In this recipe, you will access Iceberg tables from Spark running on an EMR cluster. Much like any other Spark environment, using Iceberg with EMR requires including the Iceberg runtime dependencies for the target Spark version and configuring an Iceberg catalog using standard Spark configuration properties. Both of these can be easily achieved using EMR software settings upon cluster creation.
For the best Iceberg experience and performance, keep up-to-date with the latest EMR and Iceberg releases. This tutorial assumes EMR 6.14.0 or later.
Create an EMR cluster
There are three requirements for connecting EMR Spark to an Iceberg catalog:
- An Iceberg-capable EMR version with Spark (minimum emr-6.5.0)
- The Iceberg runtime dependencies
- The Spark configurations for your desired catalogs (see the sections on catalogs and Spark configuration).
If you are familiar with navigating the AWS web interface and documentation, you can use the AWS EMR console to fill in configurations as needed. If you get stuck, you can always use the CLI method to create an isolated cluster for running these examples.
EMR console
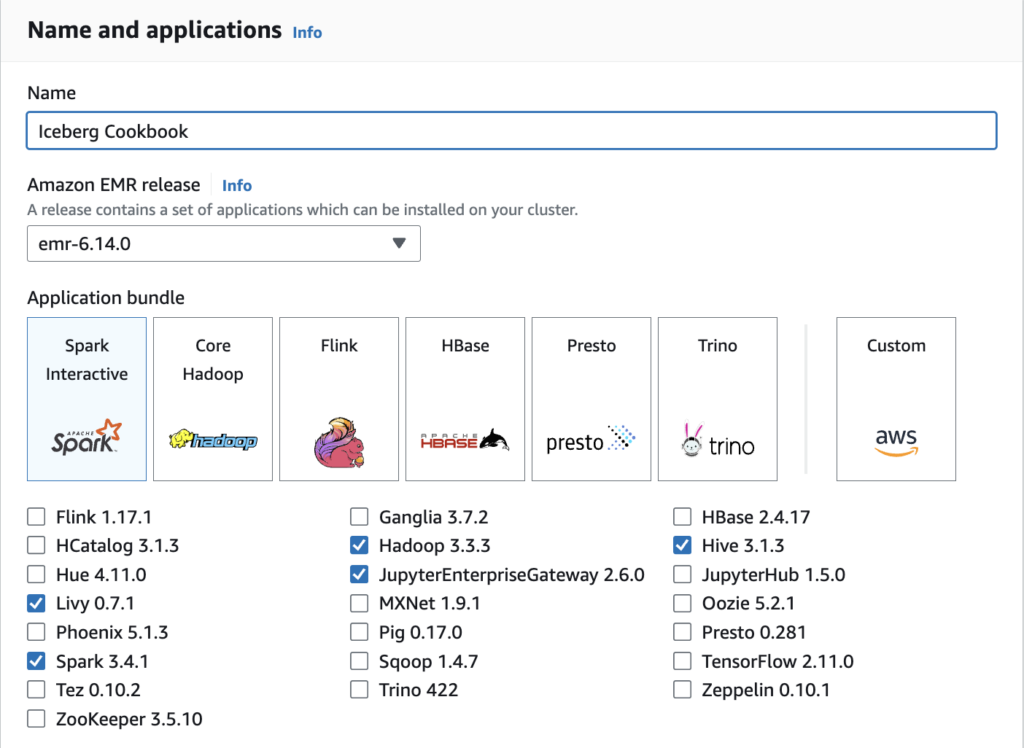
Name and applications
- Navigate to the EMR console
- Select an EMR version (recommend emr-6.14.0 or greater)
- Select the Spark application bundle
Software settings
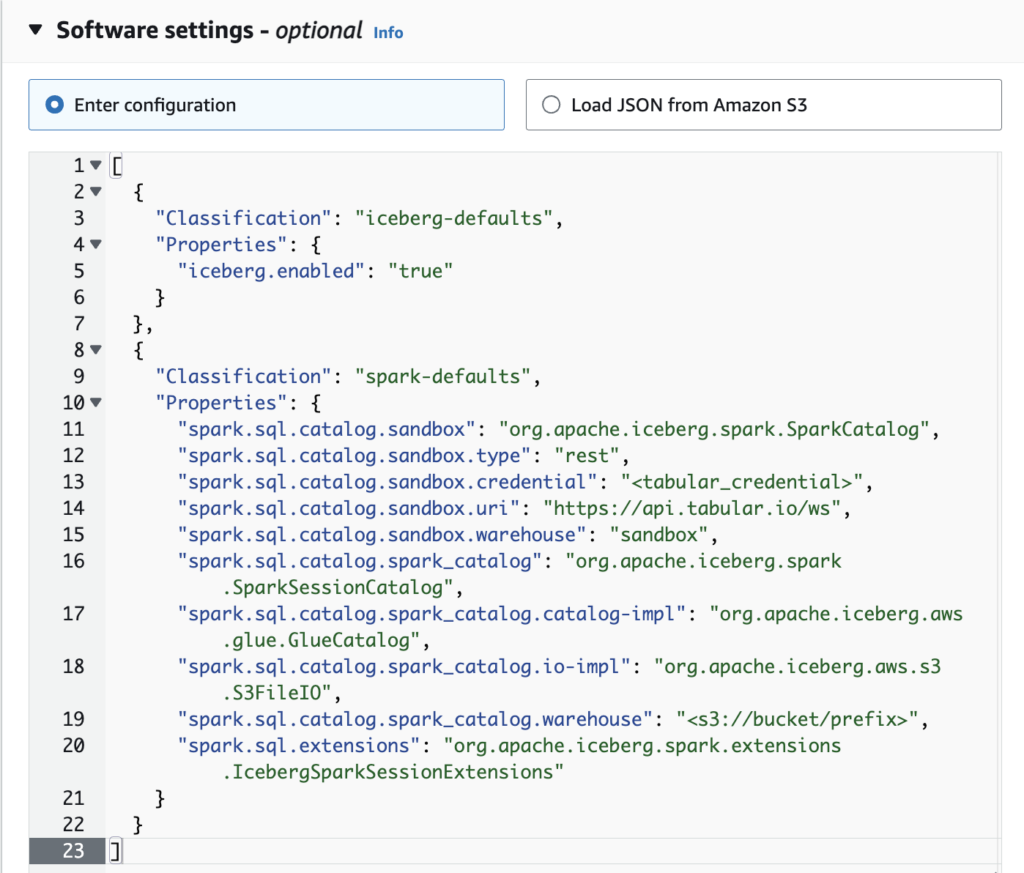
There are two important steps under software settings:
- Enable Iceberg – instructs EMR to include the appropriate Iceberg runtime libraries for Spark.
- Configure Spark – in EMR, you configure the cluster’s
spark-defaults.confhere. This example demonstrates configuring an AWS Glue catalog as Spark’s defaultspark_catalogand a Tabular REST catalog namedsandbox.
AWS CLI
To create a cluster using the AWS CLI, run the create-cluster command. Use --configurations to pass the JSON configuration for spark-defaults.conf that defines your Iceberg catalogs.
aws emr create-cluster \
--name "Iceberg Cookbook" \
--release-label "emr-6.14.0" \
--instance-type m5.xlarge \
--instance-count 2 \
--use-default-roles \
--tags 'iceberg-cookbook' \
--applications Name=SPARK \
--ec2-attributes KeyName="<aws-keypair-name>" \
--configurations '[
{
"Classification": "iceberg-defaults",
"Properties": {
"iceberg.enabled": "true"
}
},
{
"Classification": "spark-defaults",
"Properties": {
"spark.sql.catalog.sandbox": "org.apache.iceberg.spark.SparkCatalog",
"spark.sql.catalog.sandbox.type": "rest",
"spark.sql.catalog.sandbox.credential": "<tabular_credential>",
"spark.sql.catalog.sandbox.uri": "https://api.www.tabular.io/ws",
"spark.sql.catalog.sandbox.warehouse": "sandbox",
"spark.sql.catalog.spark_catalog": "org.apache.iceberg.spark.SparkSessionCatalog",
"spark.sql.catalog.spark_catalog.catalog-impl": "org.apache.iceberg.aws.glue.GlueCatalog",
"spark.sql.catalog.spark_catalog.io-impl": "org.apache.iceberg.aws.s3.S3FileIO",
"spark.sql.catalog.spark_catalog.warehouse": "<s3://bucket/prefix>",
"spark.sql.extensions": "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions"
}
}
]'
Use Spark to interact with Iceberg tables
- Once the cluster has entered into a Waiting state, connect by clicking “Connect to the Primary node using SSM” in the EMR console or SSH into the primary EMR node
- Validate the Iceberg runtime jars are present
> ls /usr/lib/spark/jars/iceberg*
/usr/lib/spark/jars/iceberg-emr-common.jar /usr/lib/spark/jars/iceberg-spark3-runtime.jar
- Validate the default Spark catalog configuration
> cat /etc/spark/conf/spark-defaults.conf | grep spark.sql.catalog
spark.sql.catalog.spark_catalog.io-impl org.apache.iceberg.aws.s3.S3FileIO
spark.sql.catalog.spark_catalog org.apache.iceberg.spark.SparkCatalog
spark.sql.catalog.spark_catalog.catalog-impl org.apache.iceberg.aws.glue.GlueCatalog
spark.sql.catalog.spark_catalog.warehouse <s3://bucket/key/prefix>
spark.sql.catalog.sandbox org.apache.iceberg.spark.SparkCatalog
spark.sql.catalog.sandbox.catalog-impl org.apache.iceberg.rest.RESTCatalog
spark.sql.catalog.sandbox.uri https://api.www.tabular.io/ws
spark.sql.catalog.sandbox.credential <redacted>
spark.sql.catalog.sandbox.warehouse <tabular_warehouse_name>
- Run the Spark Shell and validate that we are able to connect to the Iceberg catalogs
USE glue;
-- Time taken: 1.135 seconds
USE cookbook;
-- Time taken: 1.035 seconds
SHOW CATALOGS;
-- cookbook
-- glue
-- spark_catalog
-- Time taken: 0.388 seconds, Fetched 3 row(s)
Advanced topics
Using a specific version of Iceberg
Starting with EMR version 6.5.0, you can enable Iceberg by setting the appropriate EMR configuration. This configuration will ensure that a compatible version of the Iceberg runtime jar is included on all nodes in the EMR cluster.
The version of Iceberg that is included is based on the EMR version for the cluster (details). Using this method ensures that the Iceberg version aligns with the version of Spark or Apache Hive that is deployed on the cluster.
However, you are limited to the version specified by the EMR version of the cluster. If you want to use a specific Iceberg version, you will need to exclude this configuration and use an alternate method for deploying the Iceberg library on the cluster. You must ensure that the version of the Iceberg runtime jar matches the Spark version deployed on the cluster, the examples below assume an EMR cluster with Spark version 3.4.
Method 1: Specify as part of the default cluster Spark configuration
spark.jars.packages: org.apache.iceberg:iceberg-spark-runtime-3.4_2.12:1.4.2
Method 2: Specify as a package when launching a Spark session on the cluster
spark-sql --packages org.apache.iceberg:iceberg-spark-runtime-3.4_2.12:1.4.2
Using AWS Glue as a Spark session catalog
If you want to use AWS Glue to provide a Spark session catalog, in the AWS Glue Data Catalog settings check the box for “Use for Spark table metadata”. Then configure the Glue catalog for Spark as we did in the first section of this recipe, but replace org.apache.iceberg.spark.SparkCatalog with org.apache.iceberg.spark.SparkSessionCatalog.
Using a Spark session catalog enables Spark to work with both Iceberg tables and Hive tables registered in Glue.
See the recipe on configuring Spark for more details.
EMR configuration reference
iceberg-defaults
iceberg.enabled– (default: false) this setting is used to include the Iceberg runtime libraries packaged in the EMR version you’re using.
spark-defaults
spark.jars.packages– Comma-separated list of Maven coordinates of jars to include on the driver and executor classpaths. The coordinates should be groupId:artifactId:version (e.g. org.apache.iceberg:iceberg-spark-runtime-3.4_2.12:1.4.2).spark.sql.catalog.<catalog-name>.*settings create an Iceberg catalog and configure it. (See the recipe on configuring Spark for more details.)spark.sql.defaultCatalogsets the initial catalog for new spark sessions.spark.sql.extensions– this adds extensions to Spark’s SQL syntax to set a table’s write order, alter partitioning, and run stored procedures likemigrateandexpire_snapshots. In Spark 3.4 and earlier, it also enabled row-level plans likeUPDATEandMERGE.