
The first part of this series introduced CDC table mirroring using the change log pattern. It omitted an important part of any CDC approach that often goes overlooked: transactional consistency. It’s important to address consistency early and to account for it in the design phase. It’s not difficult to incorporate and is well worth the time. Otherwise, you’ll waste a lot of time tracking down problems that never show up in tests — elusive data gremlins.
Eventual consistency causes data gremlins
Here’s an example of a data gremlin in a CDC pipeline with two tables. This query writes a daily summary of new bank accounts based on where each account was opened:
INSERT INTO new_account_summaries
SELECT
s.branch AS branch,
current_date() AS creation_date,
count(1) AS new_accounts
FROM accounts a JOIN signups s ON s.acct_id = a.acct_id
WHERE a.created_on = current_date()
GROUP BY s.branch
Over time, the data in new_account_summaries appears to drift: the results no longer match running the exact same query on the original mirrored tables. What’s going on?
The problem is that inner joins omit rows with no match. If signups are delayed reaching the CDC mirror table then the query will silently ignore accounts. The problem persists into the downstream table of daily summaries. Even if the accounts mirror is up-to-date and accounts are created in a transaction with signups, they may not be counted.
Hopefully signups aren’t an important part of the quarterly reporting!
The root cause is mismatched expectations. Data engineers and analysts using a mirror table assume transactional consistency — that the relationships from the source database are guaranteed in the mirror tables. If there are no such guarantees, then the mirror tables are only eventually consistent. If you’re building a CDC pipeline, the choice is to either make those guarantees a reality or to train everyone how to know when it’s safe to run queries.
Understanding transactional consistency
To understand the problem more clearly, let’s use the accounts table example from the prior CDC post with a couple of modifications. First, there’s a new transaction ID column, tid, that shows both transaction groupings and their order. Second, changes are limited to just transfers between accounts, assuming there are no deposits so that our example SQL is smaller.
| op | tid | changed_at | account_id | balance |
|---|---|---|---|---|---|
1 | U | 344 | 2023-06-01T14:12:01 | 5 | 1442.08 |
2 | U | 344 | 2023-06-01T14:12:01 | 10 | 5351.22 |
3 | U | 345 | 2023-06-01T14:13:44 | 3 | 1900.31 |
4 | U | 345 | 2023-06-01T14:13:44 | 2 | 8124.50 |
... | ... | ... | ... | ... |
Banks are notoriously fussy when money goes missing; nothing upsets a regulator more than the appearance of creating cash from thin air. Everything must add up — to the penny. Without money coming in or out of the bank, the total amount of money should be constant and should match the source table. Here’s a query to check this on the mirror and source tables:
SELECT sum(balance) AS total_assets FROM accounts
Oh, no! A data gremlin: the query’s result doesn’t match the source and it fluctuates as the mirror updates.
What’s happening is each bank transfer is performed in a database transaction (such as TID 344) with two parts: subtracting the amount from one account (row 1) and adding it to another (row 2). The updates are separate records and when they’re written using completely separate UPSERTs the mirror can show inconsistent results.
This example illustrates the fundamental problem behind transactional consistency. If any transaction is partially applied, then the mirror table is in an inconsistent state — one that never existed in the source database.
Commit alignment and transactional consistency
To fix the problem and provide transactional consistency, the data in the mirror table must be aligned with the source transactions. Either all the updates for a transaction are applied or none are. In the abstract, aligning commits with the stream of transactions looks something like this:
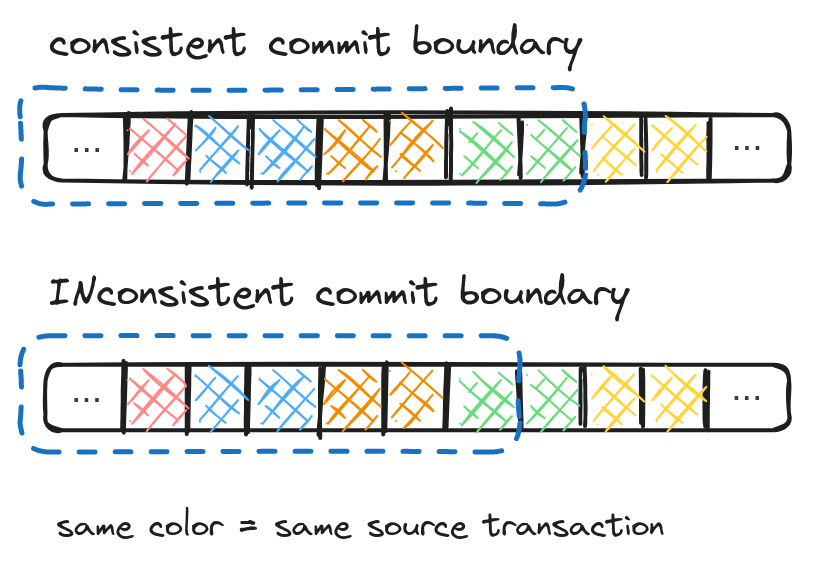
In practice, trying to provide transactional consistency by aligning commit boundaries is a mistake. Modern streaming systems such as Apache Kafka organize messages into topics and then break down those topics into partitions to distribute work. This makes the alignment problem an order of magnitude harder because changes from a transaction end up in more than one partition (or even topic), and those partitions may be processed at different rates depending on workload.
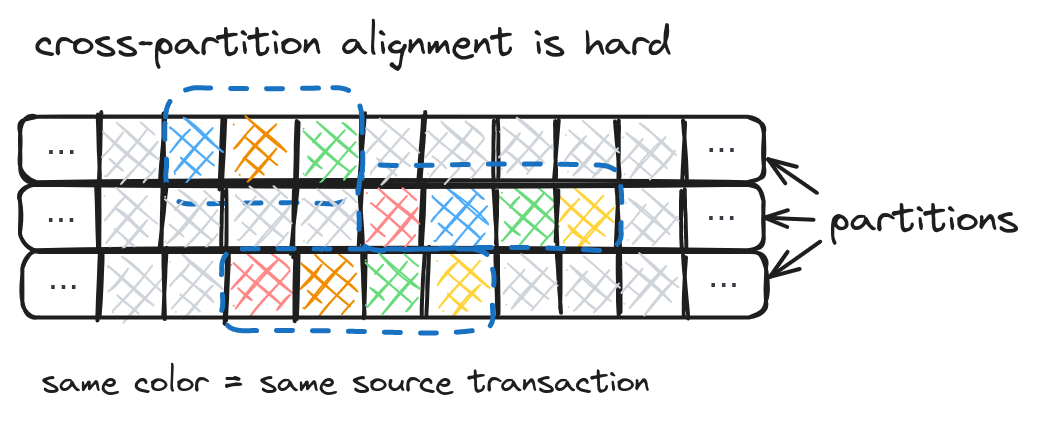
Aligning checkpoint boundaries with transactions in the data in systems like Apache Flink is just not feasible. One worker running behind could delay an entire commit for an indefinite amount of time.
An easier method for ensuring transactional consistency
A far less complicated solution is to store the source transaction ID with each change and then filter at read time for the set of transactions where all changes have landed. This approach separates concerns: the writer delivers records quickly and reliably, without complicating that responsibility with an additional set of transactional requirements. Instead, the downstream reader handles transactions by ignoring any that may be incomplete.
To know which transactions may be incomplete, this approach uses a “valid through” transaction ID. Since transaction IDs are monotonically increasing, the valid through ID is one before the lowest transaction ID last processed across all partitions. If a change for 343 was seen in a partition, then there aren’t any more changes for 342.
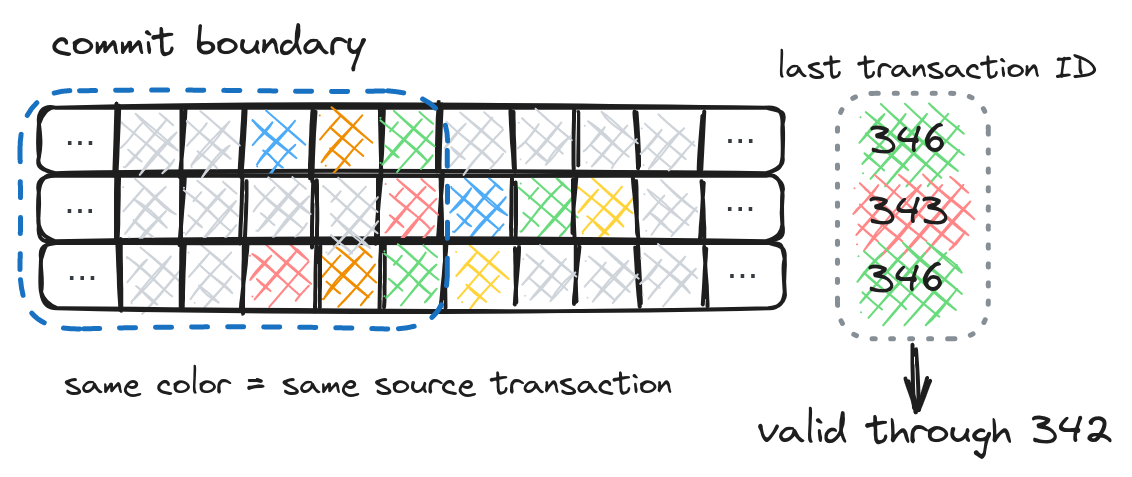
Building on the change log pattern from the prior CDC post, updating to ensure transactional consistency means adding a filter to the mirror view:
WITH windowed_changes AS (
SELECT
op,
account_id,
balance,
changed_at,
tid,
row_number() OVER (
PARTITION BY account_id
ORDER BY tid DESC) AS row_num
FROM accounts_changelog
)
CREATE VIEW accounts AS
SELECT account_id, balance, changed_at, tid
FROM windowed_changes
WHERE row_num = 1 AND op != 'D' AND tid < 342
An added bonus is that this technique is more powerful than just ensuring consistency within a source transaction. The transaction ID is valid across tables in the source database, so the same transaction ID can be used to synchronize multiple mirror tables. That guarantees consistent states across tables to prevent consistency errors like the join problem above.
Expectations in CDC pipelines
As I noted above, guaranteeing transactional consistency is really about meeting data platform users’ expectations — infrastructure should have no unpleasant surprises. Data gremlins not only waste time, they also erode trust that any data product is reliable. Building consistency into CDC architecture is not hard. But it impacts the final design — which is why we needed to discuss consistency before jumping in to the topic of the next post in our CDC series: the CDC MERGE pattern.
A brief aside on the subject of meeting user expectations: There are expectations to watch out for beyond consistency guarantees. The next largest source of data gremlins is schema evolution, which is particularly important for table mirroring. People expect to be able to mirror not only data changes but schema changes as well. If those schema updates bring back zombie data — well, that’s a very unpleasant surprise. Fortunately, Apache Iceberg has always guaranteed safe schema evolution behavior that matches the behavior in upstream SQL tables.
In fact, by implementing SQL behavior Iceberg prevents many more data gremlins. So beginning with the next post we’ll examine CDC strictly within the context of using Iceberg.


