Tripling Query Performance on Apache Iceberg at Datto
How Tabular Sped Queries, Lowered Costs and Simplified Data Architecture
Datto is a Kaseya company, which offers security and cloud-based software solutions to managed service providers. Its products are used by managed service providers who in turn serve businesses of all sizes around the world.
To deliver its services, Datto has numerous endpoint agents that transmit data into their AWS data lake, generating 150,000 daily events.
BENEFITS
- 2-3X reduction in p50 and p99 query times
- Simplified architecture
- Code-free migration in weeks
There were 3 key use cases: one was search and two were analytics. All were customer-facing. The search use case was investigating alerts; an analyst needs to identify any similar events occurring elsewhere on the network that may indicate a more widespread issue.
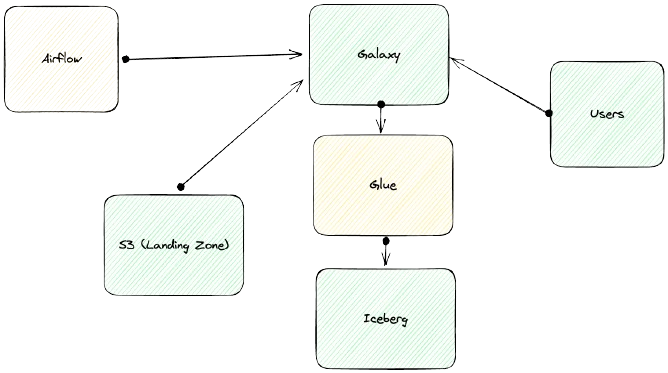
Datto’s architecture originally relied on AWS EMR. Then they adopted Starburst Galaxy as a new query engine. Starburst Galaxy was also used to ingest the data, with data preparation and job orchestration occurring through a large number of Airflow jobs.
The problem
The primary issue with this architecture was query performance, with a secondary concern around architectural complexity.
Query speed
Datto’s data team was not happy with the query performance of their system. Queries were averaging 30-60 seconds, but at times would exceed several minutes, creating a serious risk of customer dissatisfaction.
Cost
Costs were also too high. An analyst would investigate an issue and their queries would scan 150,000 JSON files in order to return only 100-200 rows. This operation was becoming a substantial amount of the company’s overall Amazon S3 bill.
Ingestion latency
Data was loaded via batch ingestion, and around 400 SQL statements would need to run against each batch, orchestrated using Airflow. Besides being a source of complexity and potential failures, the Airflow jobs put a lower bound on how quickly data could be made available for query, since attempting to reduce latency through more frequent, smaller batches would create an unsupportable number of Airflow workflows. Datto considered moving to event streaming, but felt that administering Apache Kafka would merely swap one source of complexity for another.
Solution
Move to Apache Iceberg
Based on Starburst’s recommendation, they began experimenting with Apache Iceberg tables, managed via the AWS Glue catalog. They were excited about Iceberg benefits such as time travel, snapshot rollback and dynamic partitioning.
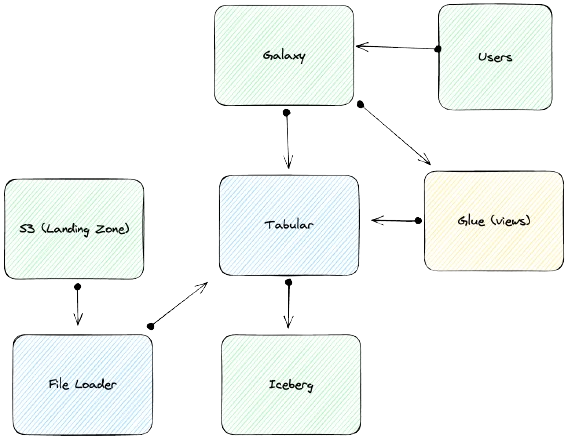
Move to Tabular for Iceberg optimization and ingestion
With a small data team, Datto they knew they didn’t have the resources to manually optimize their Iceberg storage. Plus, they saw the Tabular File Loader as a way to reduce ingestion latency while ridding themselves of managing Airflow jobs. In their new architecture, Tabular File Loader ingests from S3 buckets every 5 minutes without requiring orchestration. The Tabular Catalog replaces the Glue catalog. Glue is used to materialize views for query by Starburst Galaxy.
Quick, no-code deployment
The performance issue was such an urgent concern that the Datto team needed to transition their architecture as quickly as possible. They took advantage of Tabular’s table-in-place migration to move tables from Glue to the Tabular catalog and then point their materialized views at the new catalog. They migrated in a matter of weeks without needing any custom code.
Benefits
“The value of Tabular is the File Loader plus the table lifecycle management that includes compaction, compression and all that fun stuff I don’t have to think about.”
– Benjamin Jeter, Data Architect, Datto
Queries return 2-3 times faster
Datto’s median query time (p50) fell to 10 seconds and p99 fell to 15 seconds, each at least 4X better than before and even two or three times better than what they expected when they scoped the project.
Bending the cost curve
In the first month after implementing Tabular the S3 storage bill incurred by Datto, which had been inexorably heading upwards, began to fall, in spite of continuously growing data volumes from existing customers, and new customers being added.
“Tabular is substantially faster at a lower cost.”
Benjamin Jeter, Data Architect, Datto
Simpler architecture, less data engineering
Removing Airflow allowed Datto to decommission hundreds of DAGs that were adding complexity to the architecture. Plus, Datto’s data engineering team doesn’t need to manage the complexity behind Iceberg such as storage optimization and table maintenance.