
Motivation
Seemingly every day, more people across the business are using more data in more ways to deliver value. At the same time, regulations and consumer expectations around data privacy, governance and compliance are steadily increasing. This puts an organization’s data leaders in a very challenging position. How do they deliver on expectations for data to deliver ever more value to the business while at the same time ensuring they are not exposing the company to massive risk?
In this series of posts, we will outline best practices for taming the complexities of securing next generation data architectures while also highlighting some common anti-patterns.
- Part I – Secure the data, not the compute (you are here)
- Part II – Implementing least-privilege access
- Part III – Role-based access control
Secure the storage layer
Let’s start with the #1 best practice: secure the data, not the access.
This is one of those concepts which seems obvious once we understand it, but it is not how most data systems work today. Instead, the typical pattern is to secure every method of access independently.
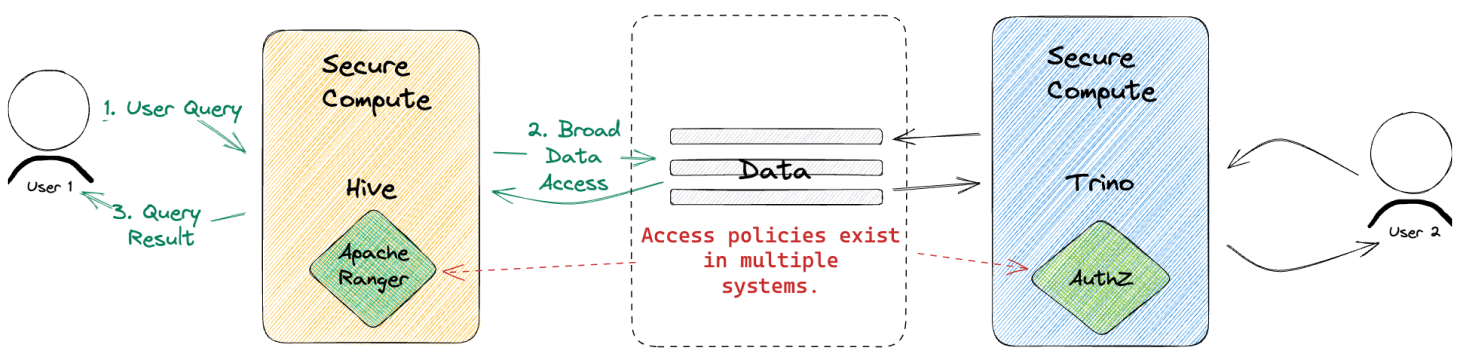
We grant a compute engine, e.g. Hive, full access to the underlying storage and then use policies in something like Apache Ranger to authorize access to the data needed by Hive queries. Ranger stores the access policies, but compute engines like Hive must support checking with Ranger at runtime to enforce those policies.
The main problem with this approach is that for each new compute engine that needs access to data, we have to repeat this pattern. But each system exposes slightly different sets of privileges and each has its own way of defining and managing access.
Ranger, for instance, has a unique set of resource types and privileges and only works for Hadoop based tools. Data stored on S3 or other object stores isn’t supported. This leaves us in an undesirable state: multiple compute environments have broad access to our data AND we have to try to keep access policies in sync across these systems.
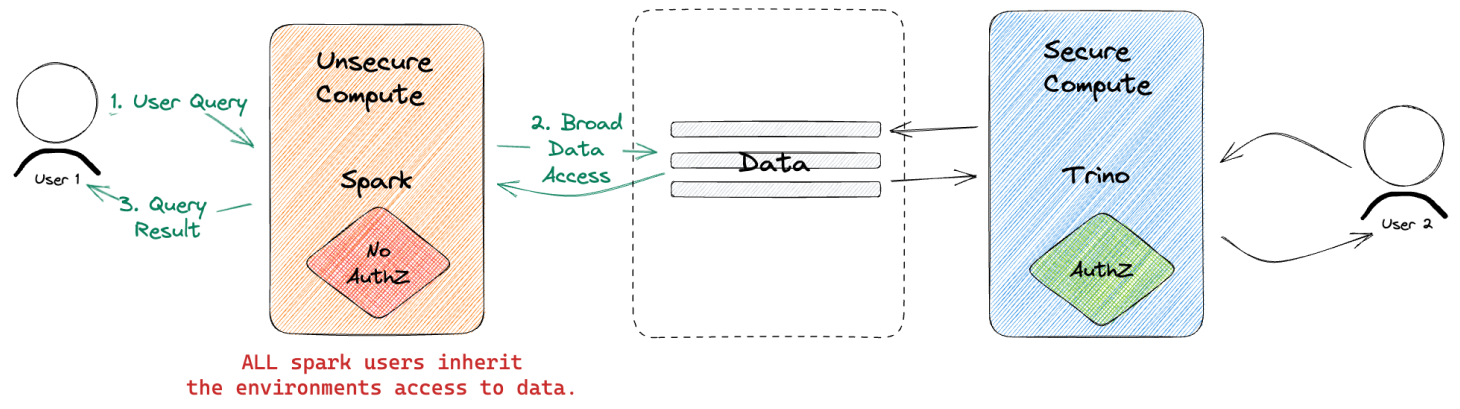
There is an even bigger challenge for environments like Spark or Python that don’t have any access controls built-in. If the environment itself has full access, there is no real way to limit what data individual users can or can’t interact with.
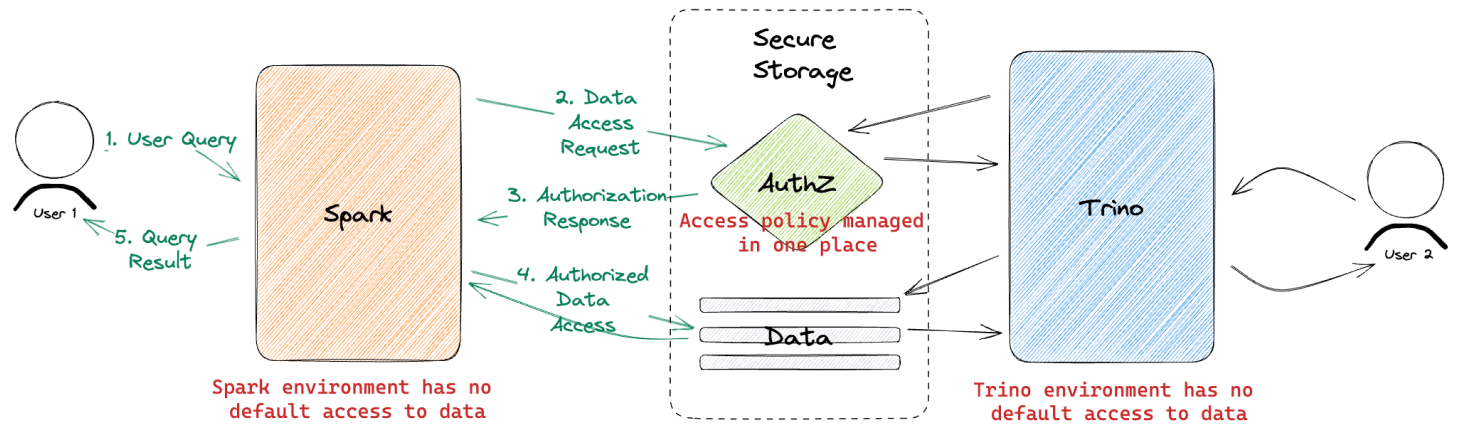
Solution: turn this pattern on its head.
Manage and enforce access policy in one place, at the storage layer. Instead of granting broad access to compute environments, grant them zero access by default.
In this setup, all read and write operations must be authorized against a single, consistent access control system. This design works equally well for sql engines like Trino, open compute environments like Spark, or even direct access from Python on a user’s local machine.
Tabular’s Approach
From day 1, we built Tabular to be a secure storage layer for Iceberg tables. It provides all of the standard SQL table-level access controls that you would expect from any database, SELECT, UPDATE, DROP, etc…. And every access to a Tabular table must be authorized, whether that be an ad-hoc query from a Trino cluster or scheduled Spark ETL job.
We achieve this by applying authorization decisions in the catalog and at the file-access level, much like an operating system does when any application attempts to read or write a file in the local file system.
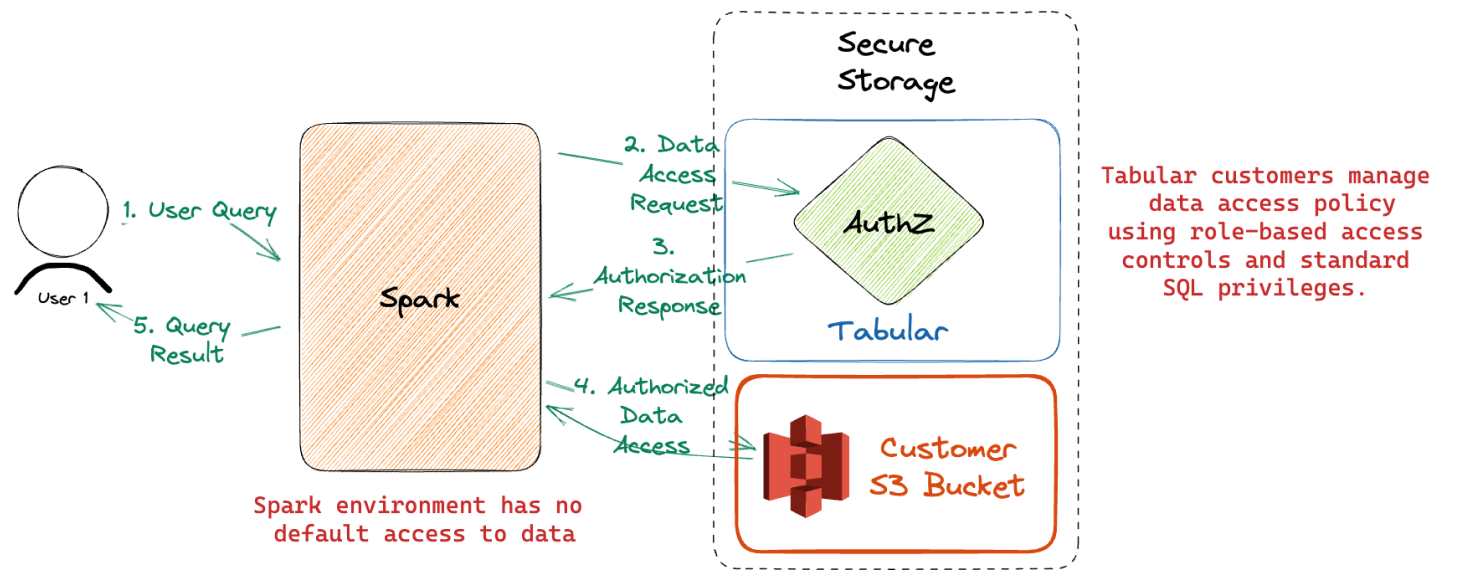
In this example, our user is attempting to access an Iceberg table stored in their S3 bucket.
- Upon attempting to read the files from the table, Spark first passes the user identity, table identifier, and file identifier to Tabular’s authorization service.
- Tabular checks the roles that are currently granted to the user and determines whether data access should be granted based on the configured access policies.
- If yes, then an authorized file access request is returned to Spark.
- Spark then uses that authorized file access request to retrieve the file from S3.
Without an authorized file access request, Spark has no direct access to the files on S3 for the table. This pattern means that data owners can easily manage who has access to which data without worrying about what compute tools consumers may choose to use. The same tables can be securely shared with data scientists doing ML with Spark or business teams using BI tools.
In truth, this same exact pattern can be used to securely share data across organizations just as easily as it can be used to collaborate across teams.
At Tabular, we leverage this capability to share Iceberg tables with our customers that contain rich information about everything going on in their data warehouse, including an audit of all authorization decisions.
Summary
- Securing the compute layer results in complex, less secure architectures
- Securing the storage layer centralizes access policy management and enforcement
- Tabular provides universal, secure storage for Iceberg tables
This is just Part I of a series of posts where we will explore the challenges and best practices around securing data in next generation data lake architectures. Succeeding posts include:


