
With the new 0.6.0 PyIceberg release, write support has been added. This blog post will highlight the new features.
Write to Apache Iceberg from Python
This blog gives an introduction to the Python API to write an Iceberg table, looking at how this is different from writing just Parquet files, and what’s next.
PyIceberg writes an in-memory Arrow table to an Iceberg table on your object store. Arrow was chosen because it is a popular in-memory format, which makes it easy to integrate into the Python data science ecosystem.
The code used in this blog is publicly available on the docker-spark-iceberg Github repository. The repository consists of a complete Docker compose stack including Apache Spark with Iceberg support, PyIceberg, MinIO as a storage backend, and a REST catalog.

First, load the default catalog that points to the REST catalog, and load one month of the NYC taxi dataset data into an Arrow dataframe from a Parquet that comes with the setup:
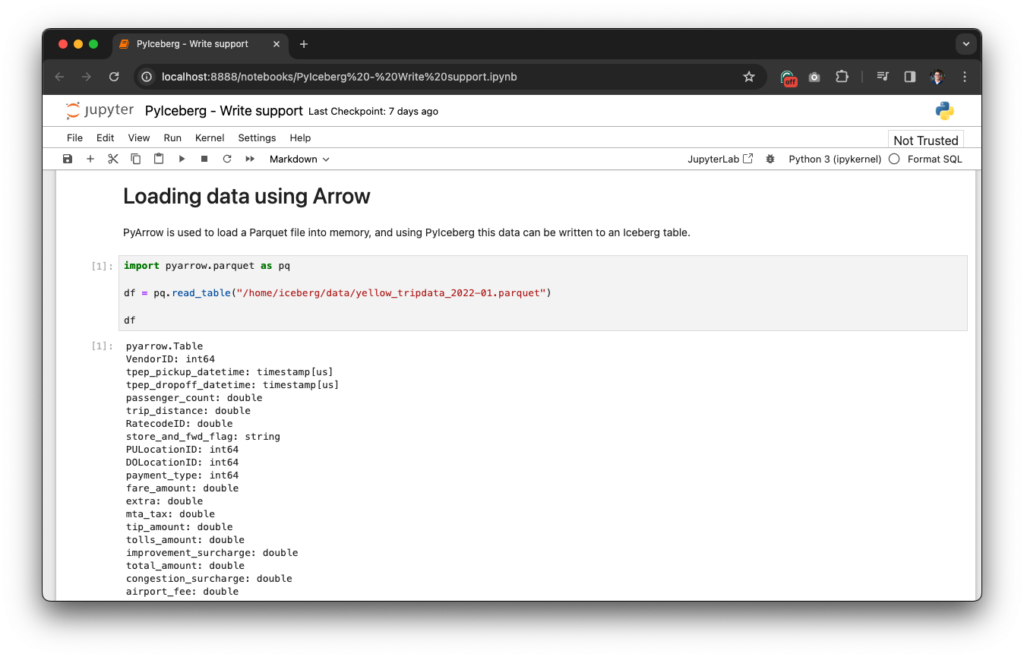
PyIceberg creates an Iceberg table based on the schema of the Arrow table:
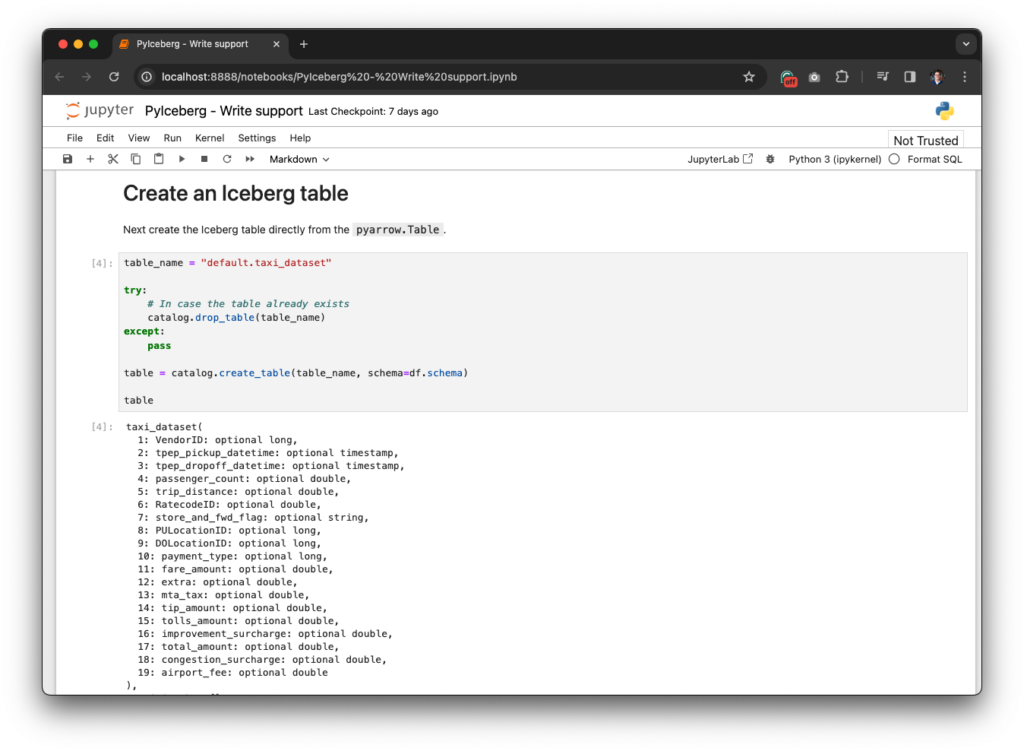
By default, this is a plain table without any partitioning, sort orders, or even data since the snapshot is null.
Write the one month of data to the table using the .append method. Since there is no data yet, the .overwrite method would yield the same result.
Now append another month of data:
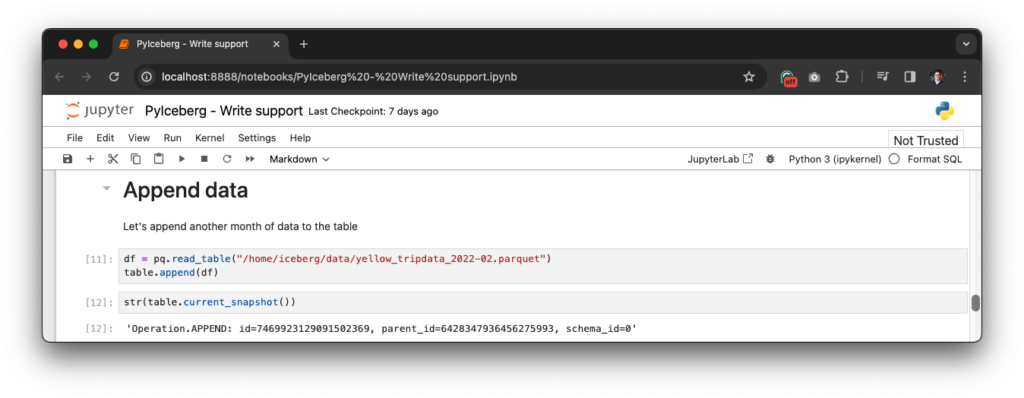
Handling schema evolution
PyIceberg leverages PyArrow to write the Parquet files. It is important to note that the schema is annotated using field IDs. Field IDs are an important concept in Iceberg to safely perform schema evolution. Instead of referencing the fields by name, it uses an immutable identifier. If you rename a column, the name associated with the identifier is updated, but not the Parquet files themselves. This guarantees safety because Field IDs are unique, in contrast with field names, and does not require rewriting existing data.
In addition, PyIceberg generates the Iceberg metadata. When writing the Parquet files, statistics are captured for each column This includes upper and lower bound, the number of nulls, and the number of NaNs. Iceberg writes these statistics in the Iceberg manifest file. These statistics skip irrelevant files during query planning, which avoids unnecessary calls to S3 to fetch this information from the Parquet file.
Imagine training a model on this data to determine the features that contribute to the size of the taxi ride tip.
First, compute the target value and add that to the table:
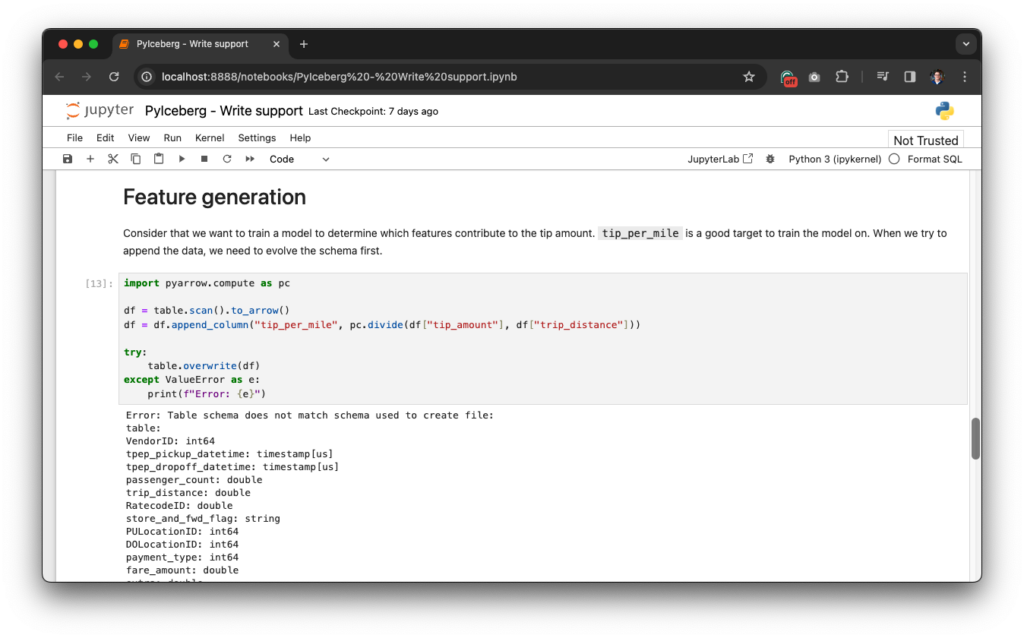
As expected, there is an error that the schema does not match. This is expected since a column was added. If you find the error awkward, don’t worry, an improvement is on the way. Now, add the column by matching it by name:
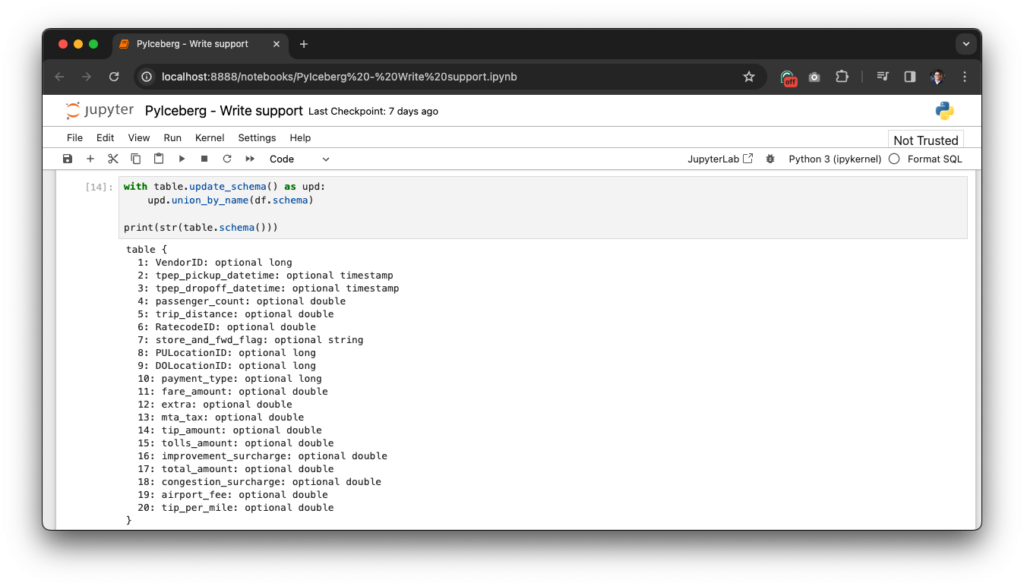
This compares the names of the columns and tries to take the union of the schema. This includes setting nullability, promoting fields, and adding new fields. An error is thrown if the schemas are not compatible. For example, consider fields with the same name, but one uses a string, while the other uses an integer. This way downstream consumers of the Iceberg tables won’t break.
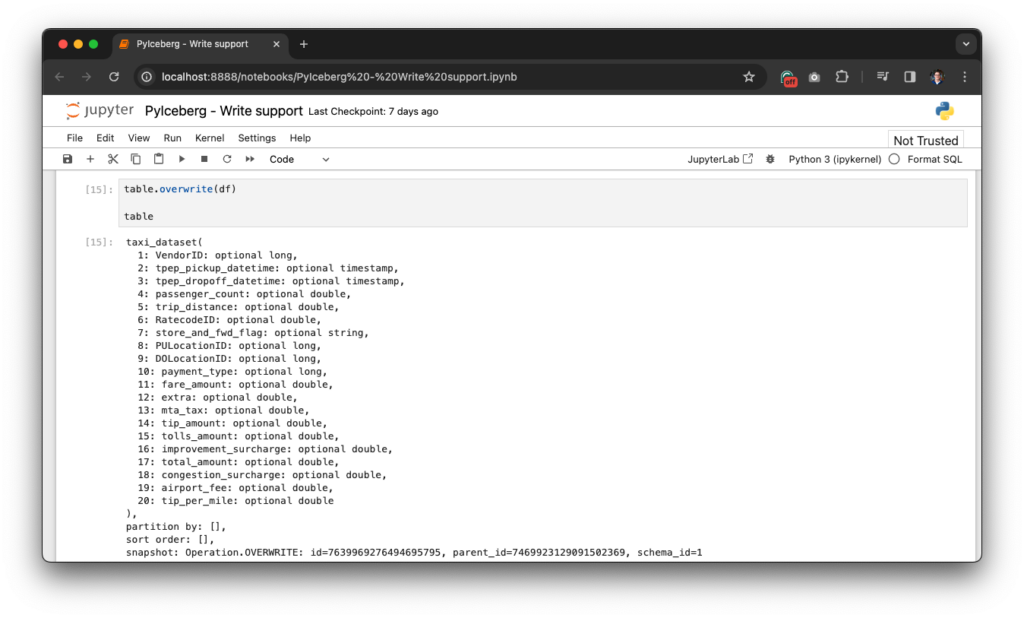
Notice that the new column has been added 🥳 After reading this blog, check out the documentation online. Also, feel free to raise an issue if you’re missing anything, or reach out on the #python channel on the Iceberg Slack.
Other new features in PyIceberg 0.6.0
An overview of other features in the new release.
Commit support for {Glue,SQL,Hive} catalog
Iceberg’s native REST catalog adds commit support in PyIceberg 0.5.0. With 0.6.0 release, the Glue, SQL, and Hive catalog reached feature parity with the REST Catalog. This gives the ability to update tables when using any of these catalogs.
Name mapping
Name mapping is a technique that can be used when the Parquet files do not contain any field IDs. This is typically used when you bulk import a lot of data and don’t want to rewrite all the Parquet files to add the field IDs. It provides a reliable way of mapping the names to IDs. The name mapping is typically stored in the table property, and will now also be picked up by PyIceberg.
Avro writer trees
This is a technical PR that adds the ability to construct Avro writer-trees. This enables PyIceberg to write files that match exactly the Avro specification even when writing V1 tables. Internally, PyIceberg handles all the tables as V2 to avoid having to implement a lot of edge cases. Using this writer tree, it can now write V1 tables as well.
Looking ahead
The first iteration of write support required building a lot of plumbing: statistics collection, Avro writers for the manifest and manifest list, snapshot generation, summary generation, etc. With 0.6.0, write support consists of append and overwrite operations on unpartitioned tables. What’s next:
- Write to partitioned tables. Partitioned writes require fanning out the writes efficiently and writing the data to its corresponding partition.
- Partial overwrites. Overwriting data in 0.6.0 consists of reading everything into memory, updating the data in the PyArrow table, and then overwriting everything back to the table. A common pattern is to overwrite a partition or a part of the data. Using partial overwrites you don’t have to load everything into data.
- Merge into / Upsert. The more sophisticated version of partial overwrites. Where an Arrow dataframe is merged into an existing table. PyIceberg leverages the metrics to efficiently operate without loading more data into memory than necessary.
- Compaction. For append or overwrite operations, PyIceberg performs a fast append. The commit is done quickly — as the name implies — reducing the possibility of a conflict. The downside is that it generates more metadata than necessary, resulting in slower query planning as the metadata grows.
Huge thanks to the community
Last, but not least, thanks to the PyIceberg community for making 0.6.0 happen: Adrian Qin, Amogh Jahagirdar, Andre Luis Anastacio, Drew Gallardo, Hendrik Makait, HonahX, Hussein Awala, Jay Chia, Jayce Slesar, Jonas Haag, Kevin Liu, Luke Kuzmish, Mehul Batra, Michael Marino, Patrick Ames, Rahij Ramsharan, Sean Kelly, Seb Pretzer, Sung Yun, tonyps1223, waifairer.


