
Happy to announce that PyIceberg 0.4.0 has been released, and is packed with many new features! PyIceberg is a pure Python implementation for reading Iceberg tables into you favorite engine.
This new release is a major step in the maturity of PyIceberg. You can now expect a major speedup of the queries, ease of use improvements, and new features. With each release, PyIceberg is getting closer to implementing the full Iceberg specification.
Enhancements include:
- Evaluation of Iceberg metrics
- Support for positional deletes
- SQL Style filters
- Peek into a dataset
- Setting table properties
- Reduced calls to the object store
- Complete makeover of the docs
Let’s dive in!
Evaluation of Iceberg metrics
Iceberg uses metrics to speed up queries. These are now also used in PyIceberg query planning. The metrics include:
- row-count
- null-count
- nan-count
- upper- and lower bounds
Here’s an example: If you run a query with WHERE ts_delivered IS NULL these metrics let Iceberg know to skip data files that don’t contain any null values for that column. This greatly reduces IO and results in a dramatic increase in query speed.
Support for positional deletes
Deletes are difficult in a world where the data lives remotely in an object store, and you’re using immutable file formats such as Parquet and ORC. Within Iceberg there are multiple ways of doing deletes, each with their pro’s and con’s.
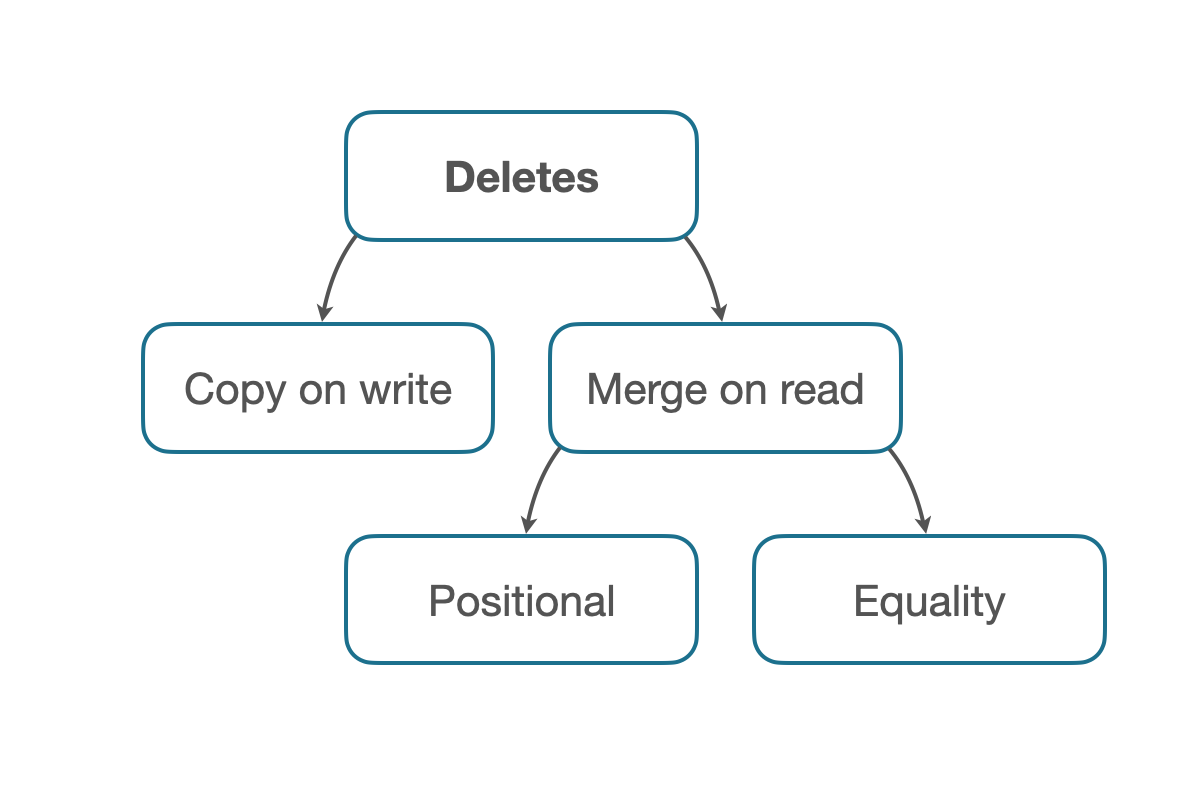
There are two main strategies:
- Copy on write: Best strategy for read-heavy tables, where there are not many commits. This reads old data, discards the deleted records, and writes a new data file.
- Merge on read: Best strategy for write-heavy tables. In this case, the original data file is unmodified but a new file is written that indicates which records are considered deleted.
- Positional deletes: Mostly used in batch-oriented jobs (Apache Spark). A file is written that contains the indices of the deleted rows.
- Equality deletes: Mostly used in streaming jobs (Apache Flink). A file is written containing the predicates of the deleted records.
PyIceberg 0.4.0 now supports positional deletes. Check this video if you want to learn more about positional deletes.
SQL Style filters
A typical query in PyIceberg looks like this:
from pyiceberg.expressions import GreaterThanOrEqual
table.scan(
row_filter=GreaterThanOrEqual("passengers", 5)
).to_arrow()
Now, with PyIceberg 0.4.0 can do SQL-style queries instead:
table.scan(
row_filter="passengers >= 5")
).to_arrow()
This way you don’t have to import the expressions and you can reuse your SQL knowledge.
Peek into a dataset
When exploring data, sometimes you want to be able just to take a look at the data without fetching the whole dataset. Now, however, you can set a limit parameter:
table.scan(
limit=100
).to_arrow()
This only reads files until the first 100 records are fetched. This makes exploring data in Iceberg tables much more responsive.
Setting table properties
Setting table properties is finally here! This long-awaited feature is a required step for write support for PyIceberg.
with table.transaction() as transaction:
transaction.set_properties(last_updated=str(datetime.now()))
This is now available for the REST catalog. Interested in contributing to the PyIceberg project? We’d love to have you! It would be great to add support for the Glue, DynamoDB, and Hive catalogs.
Reduced calls to the object store
This is a great example of where Open Source shines and helps to improve code across projects. Historically, when you profiled the read path in PyIceberg, the application made many calls to the object store. Since the goal of the Apache Iceberg Project is to reduce unnecessary IO we took a closer look. Turns out, upon closer inspection we discovered a bug in PyArrow causing it to do an unnecessary call to fetch the Parquet metadata. Make sure to upgrade to PyArrow >= 12.0.0 to see improved performance, and reduced costs on the object store.
Complete makeover of the docs
Last but not least, I’m very excited about the complete makeover of the docs. The docs have been updated with a clean new theme and much more content. We have also added examples and published the classes with the PyDocs.
Before:
As of 0.4.0:
This was a great effort by the community. You can find the docs at https://py.iceberg.apache.org/
Give PyIceberg a try!
The list on this page are just the highlighted features, there are many more bugfixes and small improvements. It’s available now on pip. For details, please check the docs site. Make sure to give it a try! If you run into anything, feel free to reach out in the #python channel on the Iceberg Slack.

