
Many powerful and polished compute engines are available today, each with its target use case. A typical organization today has a different tool for each type of workflow: ETL, streaming, online analytical processing, object storage, interactive analytics, business intelligence. Each tool has its own native format to store and catalog data and the naive approach has often been to “lift-and-load” data, usually from a central data warehouse, into whichever tool is required for the task at hand. Of course, these tools often come with their own features for transforming data and this often results in added value that gets ingested back into the central data warehouse.
An organization’s infrastructure can quickly end up with a sort of bespoke-ness to each ETL workflow, specifically at the head and tail ends. Workflows in the data warehouse drift from being standardized to the API of the batch processing tool to instead including logic for interfacing with the ingestion interfaces of the various tools that are important to their internal stakeholders.
A powerful design that’s shown to provide a more cohesive infrastructure story is referred to as “The Modern Data Stack” with a subset of these stacks being described as “The Open Data Stack”. This post describes how Iceberg, as an open table format, serves as a gravitational force that pulls these various compute engines closer to the data warehouse and eliminates the fragmentation of an organization’s data across disparate systems.
- The Catalog
- Data Enhancement Over Data Movement
- Iceberg as an Open Table Format
- The End of Lift-And-Load Workflows?
- Closing Remarks
The Catalog
In an organization with fragmented data infrastructure, the most noticeable point of variance is the data catalog. Every data tool contains some concept of a data catalog. This means a seemingly simple task of listing all datasets in an organization has an extra dimension to consider.
Iceberg, on the other hand, can provide a unified data catalog layer. The Iceberg specification and the catalog interface make it possible to integrate Iceberg catalog support into any tool. This means creating, listing, and dropping databases and tables is a consistent experience across all engines and tools. Creating a table in Spark makes it instantly available in Trino. Streaming data from your Flink application is immediately available to your Superset dashboard.
Data Enhancement Over Data Movement
An organization without a cohesive mechanism for storing and cataloging data can end up with a web of complicated pipelines that achieve nothing more than making data available in other systems.

Each simple arrow in the diagram above represents a collection of many data pipelines that span across many teams in order to move data from one system to another. The value of these pipelines purely comes from the enablement achieved from accessing the same data in a different specialized tool. There are many additional categories of tools that aren’t illustrated here such as people management, advertising, collaboration frameworks, payment systems, enterprise resource planning. The addition of each tool means more data-movement code that needs to be developed, maintained, and monitored.
When data in an organization’s warehouse is instead immediately available to a broad suite of tools, this changes the nature of the codebase developed and maintained by each data team. Data engineers can focus on extracting value from raw data and reliably producing enhanced datasets for consumption by their stakeholders. Questions such as “How do we move data from tool X to tool Y?” are replaced with important questions around quality, governance, and the value of data assets.
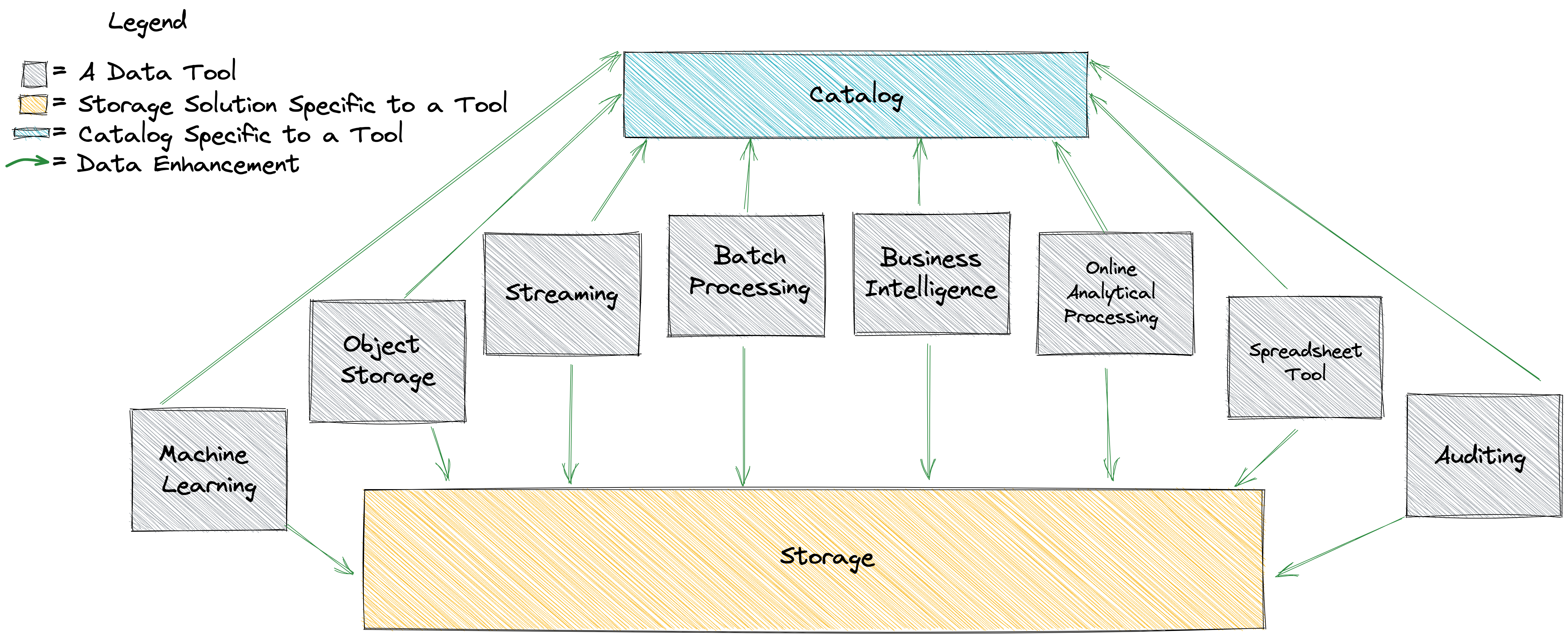
A centralized shared data catalog encourages cohesiveness between all tools. Tables that manifest from streaming applications are available for online analytical processing. The valuable business context created from batch processes can be seen by auditing tools. Data points produced by predictive models are instantly available to business intelligence reports. Most importantly, the significant engineering resources that supported data movement become available to support data enhancement–turning raw data into meaningful aggregations and metrics. This is, after all, the primary charter for almost every data team.
Iceberg as an Open Table Format
Although easy to imagine, it’s no small task to bring an infinite set of tools to a single contract for writing, reading, defining, and referencing data. The key component in achieving this is the open table format. It’s not enough for a table format to simply be open-sourced. To meet the requirements for massive adoption and integration into disparate systems and tools that differ tremendously from one another, a table format has to provide a clear and meticulous specification that ensures correctness.
Iceberg’s wide adoption is in large part due to just that–a clear specification that guides the implementations. The specification provides consistency across different Iceberg clients and runtimes which in turn allows Iceberg tables to serve as a Rosetta Stone between different compute engines.
The End of Lift-And-Load Workflows?
With demos such as ngods-stocks or my own Multi-Engine Demo, it’s tempting to think that this means the end of workflows that purely lift data out of one system and into another. In reality, there will always be systems that live on the edges of an organization’s core data infrastructure where tight integration into the data stack is not necessary. These systems will still rely on system-specific batch data movement pipelines to lift and load data to and from the data warehouse. Support for a common table format also means there are more connection points for these external systems.
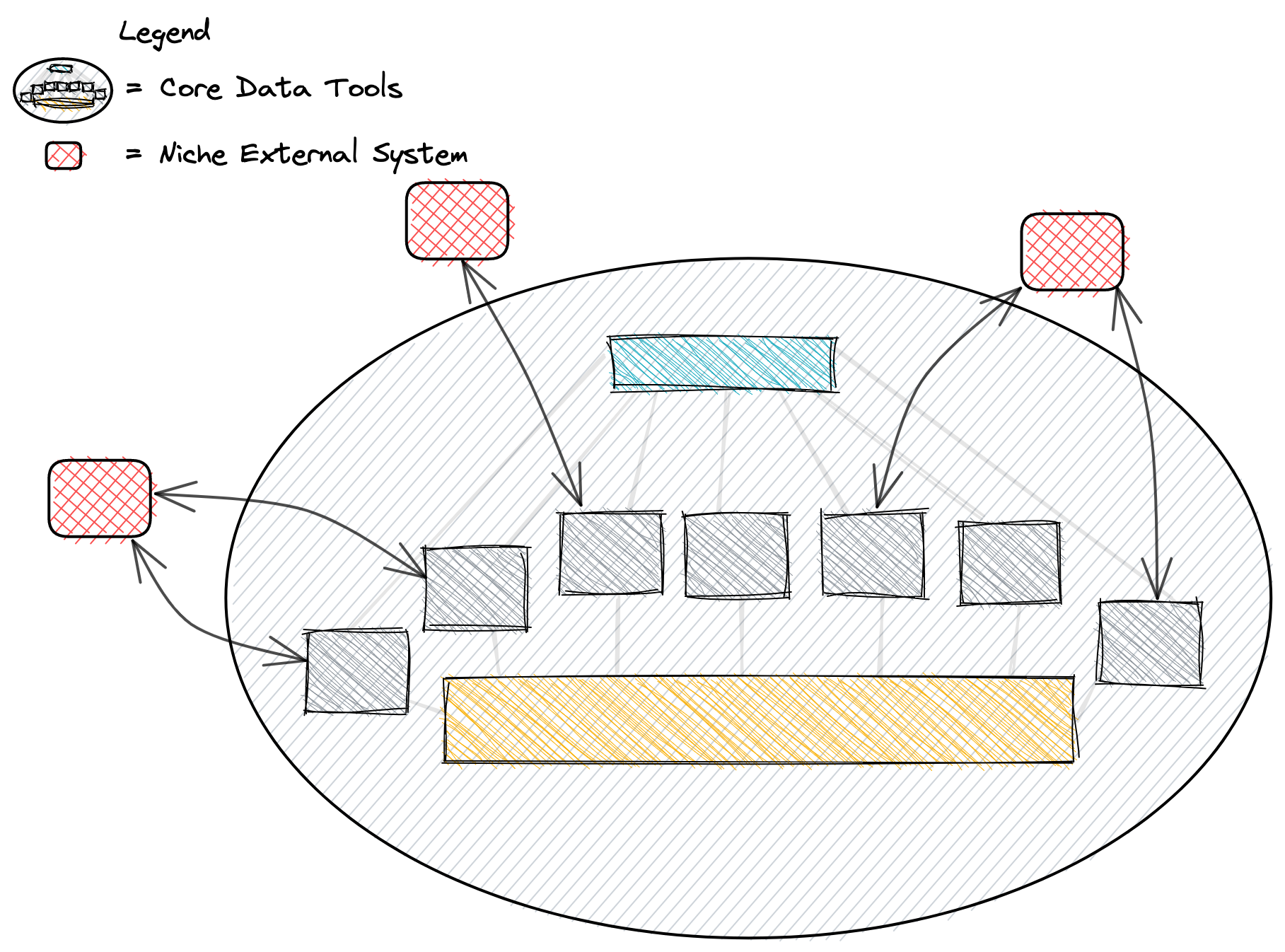
Bringing data into the data warehouse no longer enables only data engineers. When data-at-rest is directly available to many tools that satisfy many use cases for many teams, those teams responsible for analytics, business intelligence, predictive modeling, visualizations, and auditing are given full autonomy over their own projects.
Closing Remarks
The demand for an open table standard is strong and Iceberg support has grown tremendously. There’s still much work to be done and the open source Iceberg community is fortunate to include dedicated engineers from many organizations all over the world. If you have thoughts or ideas to share, or just want to drop by to say hello, the Iceberg community is a very welcoming one and you can find ways to join by checking out our community page.


