
Welcome to this series of posts that will provide an in-depth look at the new Iceberg Kafka Connect sink, developed by Bryan Keller, a Senior Software Engineer at Tabular. This blog delves into the world of Kafka and Kafka Connect, highlighting their potential applications and mainly focusing on sink connectors. We’ll discuss the merits of employing Apache Kafka Connect for routing data into Iceberg tables, a strategy that major corporations leverage for efficiently handling their streaming data. This blog will shed light on the challenges of migrating raw data into a table in real-time, the benefits of employing exactly once semantics, and the challenges and trade-offs that come with it. Stay tuned for an informative journey through the intersection of Kafka and Iceberg.
- Intro to Kafka and Kafka Connect
- Traditional challenges with existing sinks for Iceberg
- Iceberg Kafka Connect sink design elements
- Getting started
- Conclusion
Intro to Kafka and Kafka Connect
Apache Kafka is a well adopted technology that often acts as a data ingestion pipeline. It involves producing messages to Kafka, which are destined to be stored in a durable and resilient manner. Apache Kafka Connect is an effective tool for building scalable connectors to other data systems and platforms.
Invariably, a data lake is one of these destinations, enabling organizations to support both real-time analytics and complex queries across large data volumes. Classic architectures often require the same event data in both long-term analytical storage and downstream operational stores.
Traditional challenges with existing sinks for Iceberg
Exactly-once semantics
When using Kafka, one of the commonly used semantics is “at-least-once” processing. This means that if a failure occurs during the processing of a chunk of messages read from Kafka, the default behavior is to replay or repoll those messages from Kafka and process them again. This can result in processing a record twice if it has been committed before the failure occurs.
It’s not as straightforward as it may seem to avoid producing duplicates while avoiding not processing the record at all. Kafka Connect does not provide the desired “exactly-once” processing out-of-the-box, necessitating its implementation in the sink. As the name “exactly-once” semantics implies, it is the ability to consume a record from Kafka at least once but no more than once from retry efforts from either producer or consumer. As a developer of a Kafka consumer or a Kafka connector, you are responsible for integrating the write operation into the downstream system. It is important to verify if the solution you’re using only adheres to at-least-once semantics and has the potential to generate duplicates downstream.
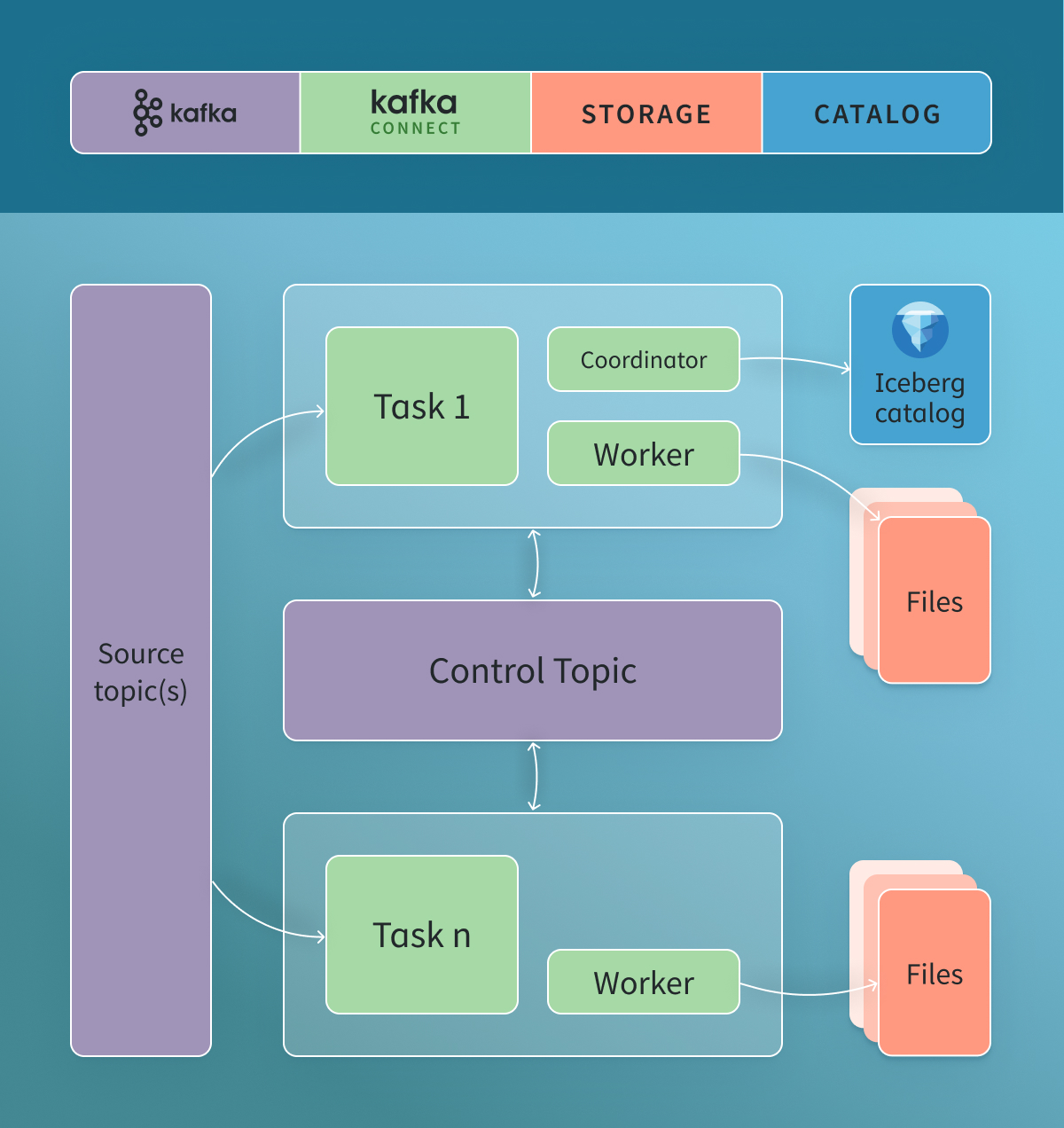
Commit coordination
Another specific issue comes down to centralizing the Kafka commit coordination. Why is that important? Without centralized commit coordination, every task that is committing to a downstream store. If the downstream database has a transactional component, it doesn’t scale well, as several tasks produce hundreds of commits occurring on a single table. This can cause contention, metadata size problems, and so forth, which is certainly the case when Iceberg is downstream. Addressing this contention is specific to the downstream location you are trying to write to. Apache Iceberg uses optimistic concurrency to achieve serializable isolation. This means that if multiple tasks try writing to a popular set of records being constantly updated, then there will be a large number of retries happening when all the tasks go to commit. Handling the commits in a centralized manner addresses this contention and facilitates a much cleaner table for consumption.
Multitable and multi-database fanout
It’s worth noting that Apache Flink is capable of multi-table writes to Iceberg tables, including exactly once semantics; however, one final limitation to discuss that is present in Flink is that you aren’t able to easily fan out across multiple tables and databases. Enabling table and database fanout can simplify your infrastructure to be able to run one job that is writing to many tables rather than having one job per table. For example, if you have a hundred tables, you can do that in one Kafka connect instance, but you would have to have a large number of Flink jobs to accomplish the same thing.
Iceberg Kafka Connect sink design elements
Addressing the prior concerns fed into the design goals for the Iceberg Kafka Connect Sink. By using a communication channel via a channel on Kafka to decouple the coordinator from the worker, we enable centralized commit coordination while simultaneously improving durability. It also lowers the number of external system dependencies in the architecture since Kafka is already included in the architecture. That coordinator then orders all the commits, gathers up all the data that’s been written, and then commits that to Iceberg from a single node.
Exactly-once processing over multiple tables
The Iceberg Kafka Connect implementation and Kafka combination provide “exactly-once” semantics to your tables, thereby eliminating duplicates. This holds true whether you’re writing to a single table, multiple tables, or multiple databases. There are still considerations to be made, such as client-side retries, which could introduce duplicates, but this is no longer the responsibility of the infrastructure. When combined with idempotency on the producer side, this can create an expectation of “exactly-once” semantics.
Control topic
The control topic plays a crucial role in coordinating commits and ensuring exactly-once semantics. The control topic is created alongside your source topic and captures information about the files that have been written by all the workers. This approach makes it a low-volume topic, considering it’s at the file granularity, thus having a ratio of one to many millions of rows.
Each record from the source topic is written to files, and the control topic then communicates which files have been written to the coordinator. This method effectively creates a commit log, similar to a write-ahead log, providing a detailed record of everything written to a table. As such, you can always go back and inspect what exactly was written to a table by reading this control topic.
Future enhancements
Currently, there’s no real support for automatically evolving the downstream table schema based on the upstream source. Once the commit for a new schema is in, then it’ll pick up the new schema and start processing it. If you need to start producing new data, you alter that table and add that column, and then the data that’s being produced with that field will just show up in the table.
Today, the producer and the consumer are decoupled in the context of adding new fields to the schema. Producers can start producing a new field, and it will be ignored by the consumer. This is both a feature and a shortcoming of the sink. Conceptually we think of the Iceberg table as the source of truth for the schema. In some cases, we may not want to pick up new fields, but enabling a mechanism that does automatically keep the schema in sync with the data does help in certain use cases where you have tight integration with the producers of the data.
Getting started
To play with this sink yourself, you’ll need to have Kafka, Kafka Connect, and Iceberg installed.
- Follow the installation instructions for the sink.
- Create the control and source topics.
- Run through the single table and multi-table fanout tutorials.
Conclusion
We hope this was a helpful introduction to the new Iceberg Kafka Connect Sink. We’ve given you an understanding of the shortcomings of previous implementations of Kafka Connect Iceberg sinks and how to get started. In the next post, Bryan Keller will do an even deeper dive into the internals of the connector to showcase the design tradeoffs in greater detail.


