
- Commits: atomicity and isolation
- The Importance of Consistency
- ACID vs _ _ _D
When I talk about Apache Iceberg and open table formats, I have a strong preference to focus on just Iceberg. I like to promote it by talking about what it does well and areas where I think it stands apart. I also dislike pointing out what other projects don’t do or don’t do very well. Open source projects can’t exist without well-meaning contributors who genuinely care and keep pouring their effort in, hoping their work not only is valuable for their own use but also helps other people. That combination of career satisfaction and self-worth is a powerful driver — I’ve been there myself, working on Parquet, Avro, Spark, and now Iceberg.
But focusing only on what one project does well is telling just one side of the story. It doesn’t actually inform people — who are trying to learn — and leaves them to infer and investigate on their own whether an alternative has a given feature or flaw. That’s not valuable for a variety of reasons, not least of which is that it does nothing to set the record straight when some information is misleading or flat-out wrong. Not addressing this allows confusion to remain, to be believed, and to be repeated.
In this post, I make the case that Iceberg is reliable and Apache Hudi is not. And the best way to do that is to contrast the design of both projects in the context of the ACID guarantees: atomicity, consistency, isolation, and durability . My aim is to accurately present the facts to educate the curious and help people make informed choices.
This post focuses on correctness guarantees. First, I’ll present the commit protocols and describe the flaws in Hudi’s approach that make it possible for failures to leak uncommitted data into the table — compromising isolation and atomicity. Second, I’ll sketch how well each project’s design supports its consistency claims.
Let’s dive right into commit protocols.
Commits: atomicity and isolation
The commit protocol is a critical component of a table format because it is the foundation for transactional guarantees. Flaws in the commit protocol compromise a format’s ACID properties.
Apache Iceberg commits
Iceberg’s approach is deliberately simple: A table is stored in a tree structure of data and metadata files, and the entire state of a table can be identified by the root of that tree. Any change creates a new tree and new root metadata file, which is then committed by an atomic swap of the current metadata for the revision. The swap ensures the new table metadata is based on the current metadata, which guarantees a linear history because each version can be replaced only once. This is a fundamental building block for serializable isolation.
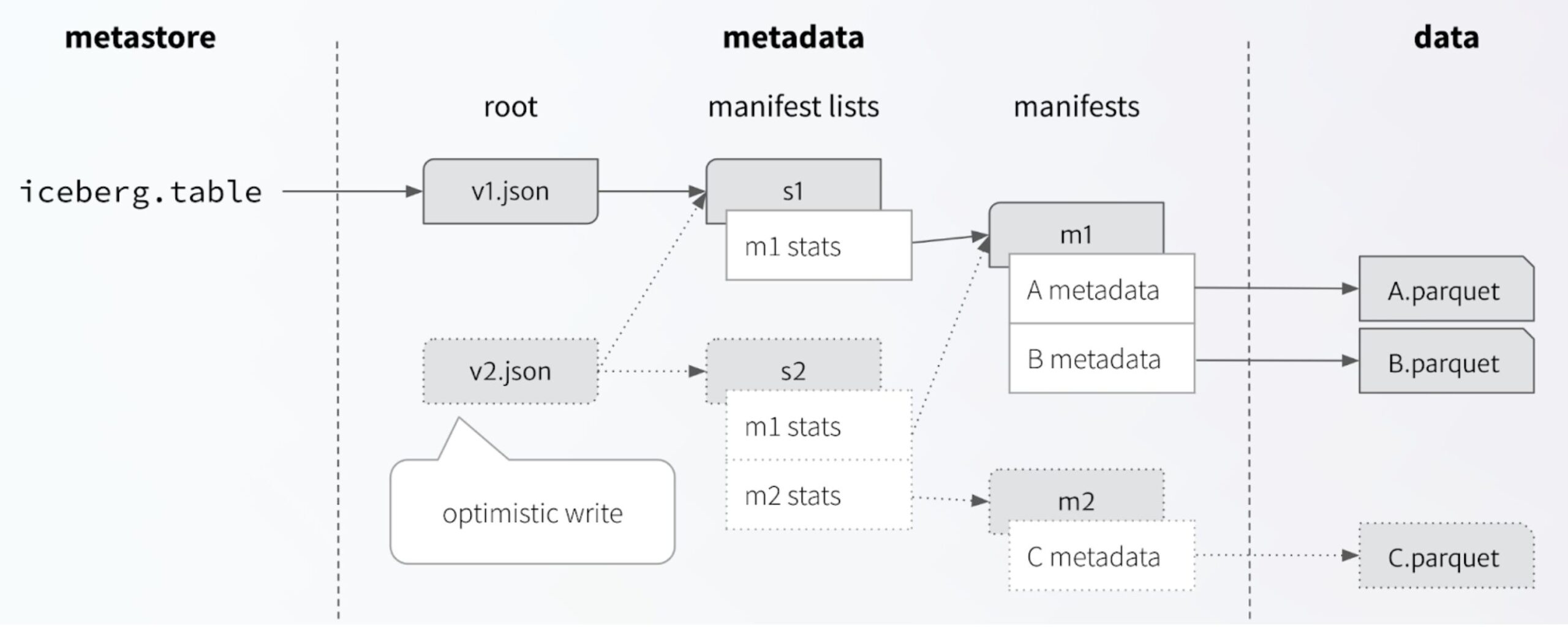
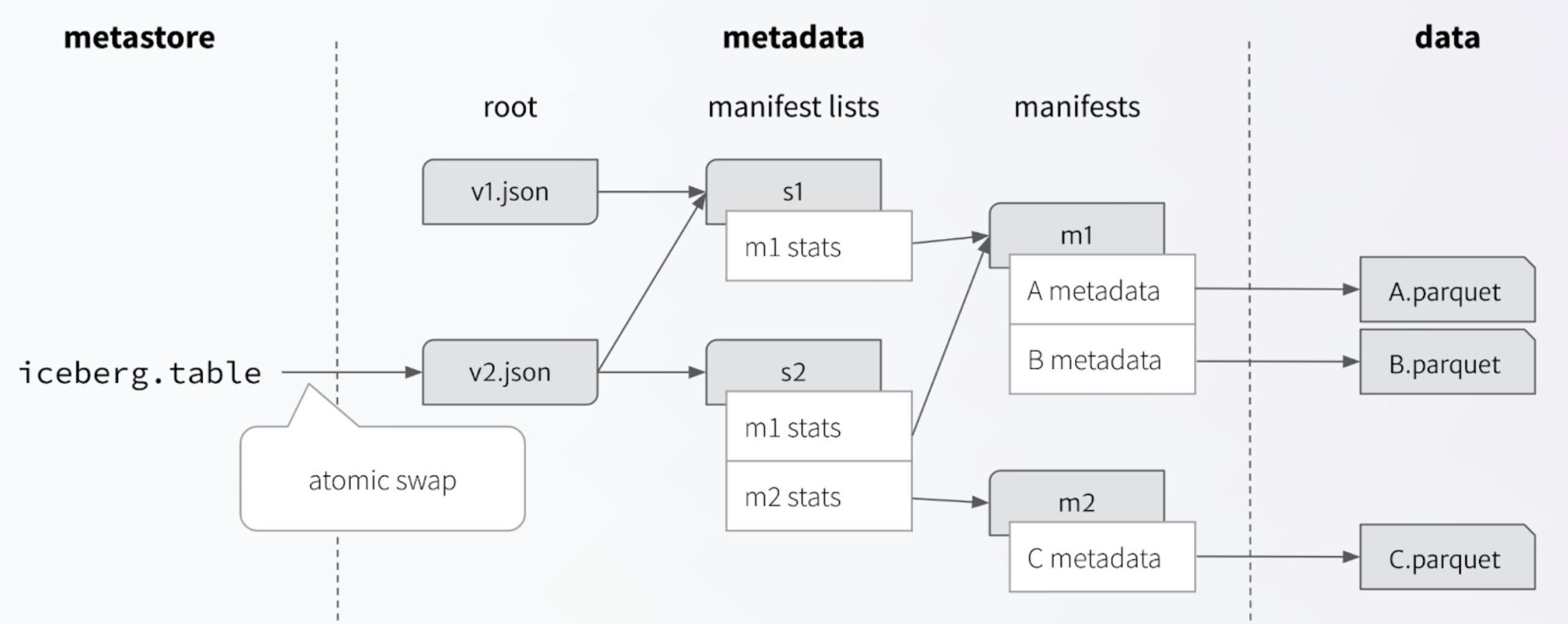
There are several options for the atomic swap, but most catalogs implement it using a database transaction. The basic idea is to use a catalog database transaction for atomicity and scale it up to support arbitrary table metadata changes by optimistically making all changes to the metadata tree ahead of time.
Using a persistent tree structure enables Iceberg to track a unique location for every data file and every metadata file. This ensures that uncommitted changes from writers never overlap and conflict. That is critical for isolating concurrent writers. And only exposing new trees using an atomic operation guarantees isolation between readers and writers.
The Apache Hudi timeline
Hudi has a more complex approach. Hudi is based around the timeline [ref], which is a folder of files that track the state of in-progress and completed commits. Each change to the table is committed by writing a .completed file to the timeline, with a filename constructed from the commit’s instant — its timestamp in milliseconds — and action type, like commit. Creating the .completed file is Hudi’s atomic operation; when it is visible in a file listing, the files associated with the commit are live.
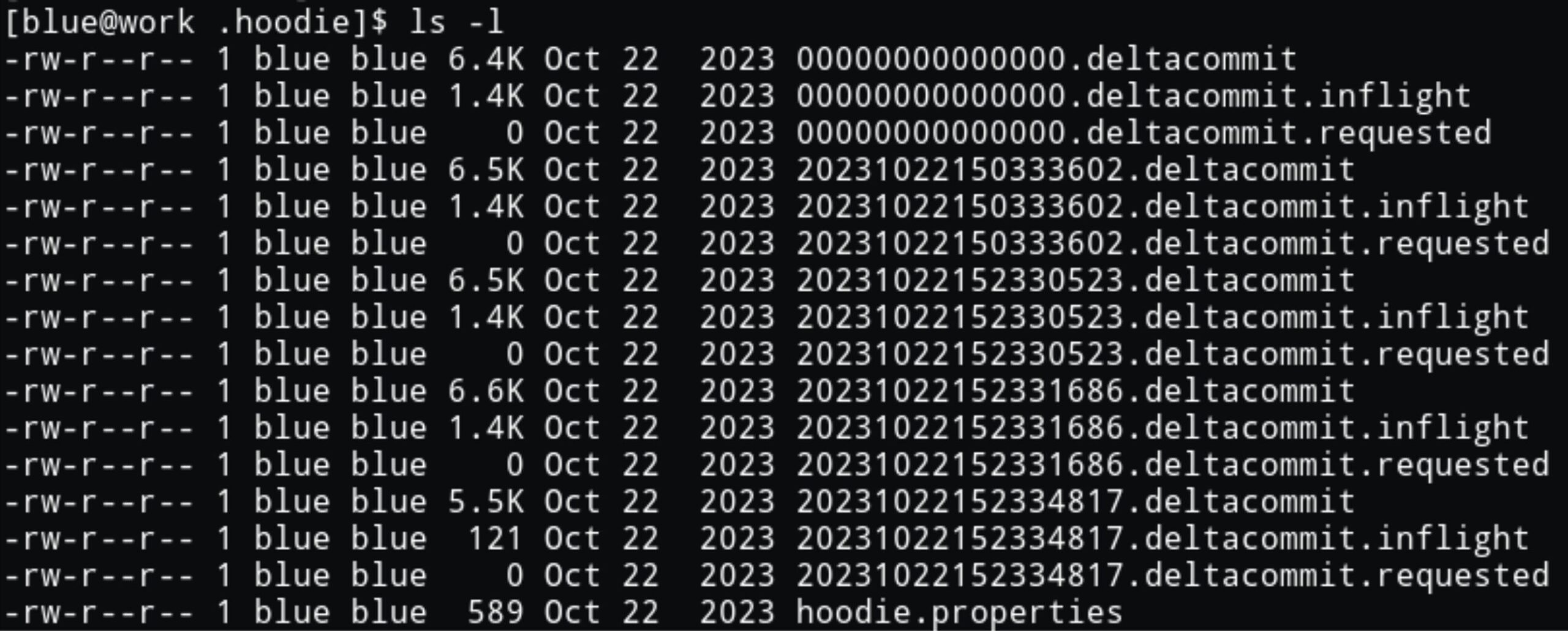
The file listing above shows an example timeline with 4 commits after the initial table creation. Hudi omits the .completed suffix from the filename, but I’ll continue to use it to distinguish between files for different states. Also note that the instant timestamps are in my local time zone.
Files are associated with a commit using a naming scheme, where the commit’s instant is included in the file name.

Reading a Hudi table is similar to reading from Hive, except for using the timeline to select only live files. The reader chooses an instant from the timeline, then lists “partition paths involved in the query” [ref] to get candidate files, and finally filters out any files from instants that have not been committed or from later instants. (There are some more requirements for different maintenance operations, but we’ll skip those to keep it simple.)
At this point, there are some potential problems and it’s important to understand how Hudi addresses them.
Instant collision in Hudi
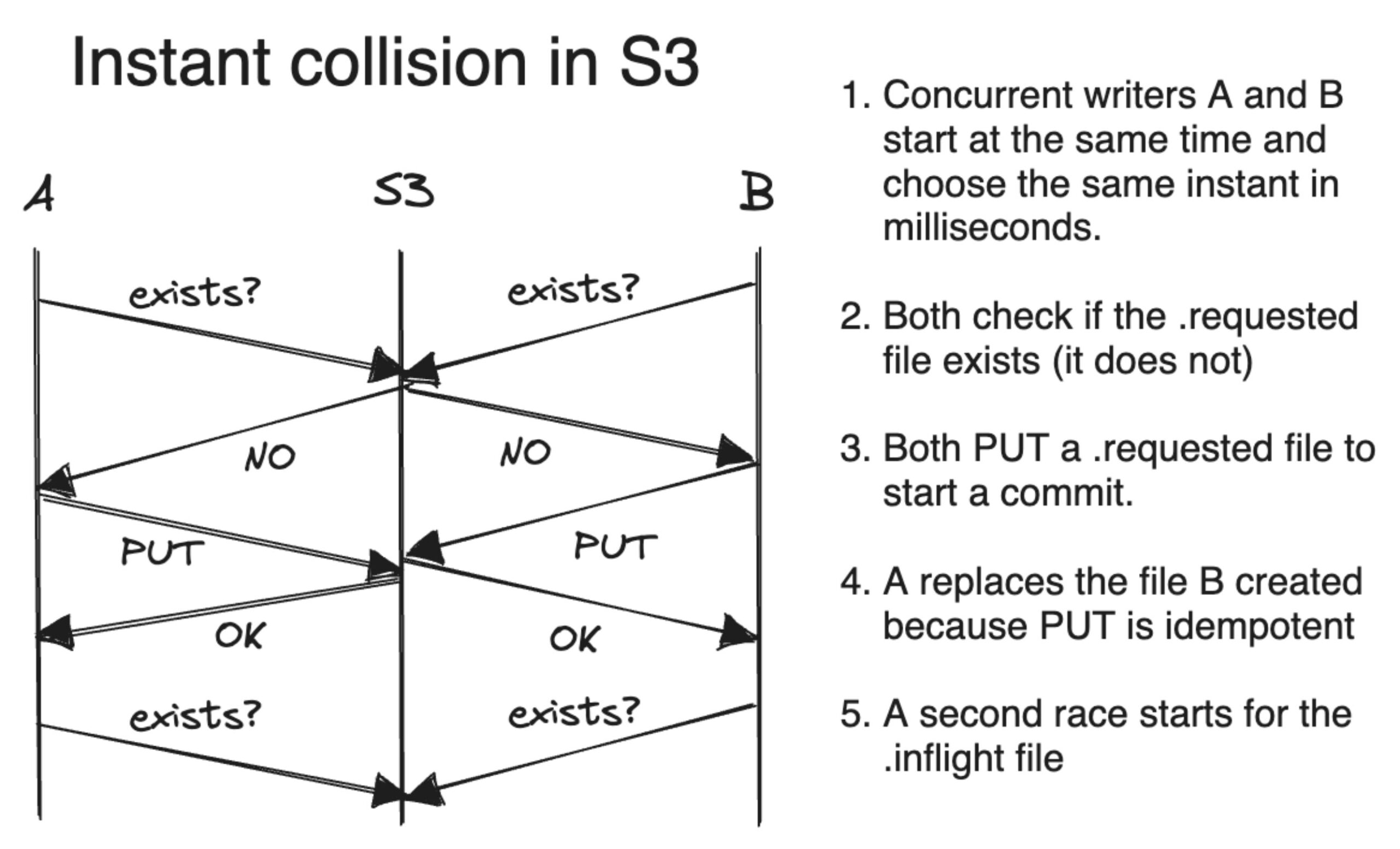
The first problem is instant collision. The timeline uses millisecond precision timestamps to name commit files, so instants and file names can easily collide. Hudi works around this in some cases using a putIfAbsent operation to ensure atomicity, but it will happily move on if that operation isn’t available. That is the case in the most common cloud storage, Amazon S3. My tests in S3 revealed that instant collision was indeed a problem.
So how does Hudi work in S3? Hudi also uses two other state-tracking files, .requested to start a commit and .inflight to summarize important information with the same instant-based naming scheme. In my testing, concurrent commits failed to create the second (inflight) file, throwing an already-exists exception instead. (The first file collision rarely caused a failure.)
Hudi can function in S3 because it’s unlikely that all three timeline files from the two committers would be created close enough in time to all succeed — but it is possible without support for putIfAbsent.
Some may object to the claim that concurrent commits might complete successfully because it leaves out a third protection: concurrency control [ref]. Concurrency control in Hudi means using a distributed lock to protect critical sections in the commit process. Both optimistic and pessimistic locking options could theoretically fix the problem by not allowing two processes to create the .completed file at the same time.
The problem is that locking is entirely optional. I only found it wasn’t turned on when double-checking tests that showed broken consistency guarantees.
Failing to enable commit safety is a big problem. This is an area where Iceberg and Hudi take significantly different approaches. In Iceberg, you shouldn’t need to think about the table format — and certainly you shouldn’t need to research how to enable transactional guarantees.
Instant collision, round 2
It’s very unlikely that two commits will complete successfully with the same instant. But there’s a far more likely problem: instant collision with uncommitted data files. Hudi associates files with commits by embedding the instant in file names, so instant collisions create files associated with both commits. And it doesn’t take much for this to happen; two writers only need to successfully create the first two timeline files. The first timeline file (.requested) is created just after the instant collision — usually, in the same millisecond — and tends to succeed. That leaves only the second timeline file (.inflight) to catch the problem. While it’s unlikely the second file creation happens at the same time, it’s likely enough to happen regularly at scale. (In addition, there are other ways for the existence check to fail, like S3’s negative caching.)
What if two commits begin writing data files for the same instant? Let’s assume that most of the time one of the writes succeeds and the other fails and removes the intermediate files. No harm done, right? Well, not quite.
As soon as one succeeds, the files for both commits are live in the table. Anyone reading the table will see incorrect results. Even worse, routine failures in the uncommitted write job can permanently leak data files and there’s no way to detect when it happens. If the uncommitted write fails to clean up a file for any reason, it will become part of the table. That can happen if a worker dies after closing a file but before completing a task. Or it could happen if the driver/coordinator crashes or is killed before cleaning up. Because uncommitted files can become visible through another commit, commits are not isolated.
Pessimistic locking can prevent collision problems with uncommitted data files, but the problem is still possible using optimistic locking, the recommended option. And, again, neither concurrency control option is on by default.
In short, because Hudi uses a filename convention to associate data with commits, inconsistent states are possible.
Can metadata tables prevent instant collisions?
Hudi experts would likely point out that Hudi can use an internal metadata table to track data files, which could fix the problem with uncommitted data. This may be a solution. But, like optional locking, there are issues with it.
To start, the spec is not clear about how using an internal metadata table works and exactly what is the source of truth.
According to the Reader Expectations section of the Hudi spec [ref]:
The lookup on the filesystem could be slow and inefficient and can be further optimized by caching in memory or using the files (mapping partition path to filenames) index or with the support of an external timeline serving system.
The plain reading of “can be further optimized” is that the metadata table is optional and that the file system is the source of truth for data files in a commit. This may avoid the problem for some readers, but the spec does not require it.
Another practical issue is that not all tables in my testing were created with a metadata table. Hudi chose not to use one in some cases (more on that later).
The files index actually makes problems worse. Now there are two sources for the same table metadata. What do you do if the files index doesn’t match the file system? Which is correct? I would argue that the files index is an optimization, in which case the file system is correct. That means the instant collision problem should resurface when the two are reconciled.
The metadata table itself is a Hudi table. What solves concurrency problems for the metadata tables? The answer is pessimistic locking. The entire metadata table update must be done while holding a lock, according to a (liberal) reading of step 6 in Writer Expectations [ref]:
- Synchronizing Indexes and metadata needs to be done in the same transaction that commits the modifications to the table.
If Hudi’s internal metadata tables are indeed the solution, they show that pessimistic locking is required for correctness.
Instant collision, round 3
So far, the risk of instant collision came from using S3 or another object store with no putIfAbsent operation. But there’s another form of the instant collision problem that could happen in any storage system. Hudi timeline files use names made from 3 parts: the instant, the action type, and the state. If two writers use different action types with the same instant, the timeline file names won’t collide. That allows two writers to use the same instant without the file system checks that help avoid the other cases. So once again, if one writer commits successfully, files from both commits are live.
There is good news: unlike the previous instant collision case, this collision could probably be detected. In the final commit process, a writer could list the timeline directory, check for an instant collision, and fail the commit if one exists.
But the primary problem is that this check isn’t required, nor is the issue mentioned in the Hudi spec.
And there’s a secondary problem with this flavor of instant collision. Because additional file system checks are necessary for isolation — to check for instant collision — the commit is no longer atomic. Using a locking scheme would restore atomicity, but the commit protocol doesn’t specify exactly what checks are required while holding the lock.
Hudi’s spec has little information about how commits work in general and doesn’t cover cases like this (and others). The closest the spec comes is discussing concurrency using locks, but those sections cover data conflict detection, not commit conflicts.
Even if Hudi checks for instant collisions, an unexpected delay could prevent that check from catching the problem. If, for example, one writer selects an instant and then blocks for minutes while a full GC runs, a conflicting writer could complete during that GC. It would pass conflict checks because the conflicting timeline files haven’t been written yet. Yes, this is unlikely. But it’s issues such as these that separate designs that guarantee atomicity from those that are just usually “okay.”
Comparing commit procedures
Before moving on to consistency, let’s pause for a high-level comparison of the commit processes. In general, a software design tends to follow one of two patterns:
- So simple that it is obviously correct
- So complex that it is not obviously broken
This is the essential difference between Iceberg and Hudi commits. Iceberg’s method of providing atomicity and isolation is simple and aims to be obviously correct. It is essentially the design of git extended to data. Hudi’s approach is so complex that it’s hard even for data infrastructure experts to tell what is safe and what isn’t.
Given the problems outlined above, I cannot conclude that Hudi guarantees either atomicity or isolation. Hudi certainly does not provide those guarantees by default — you must configure locking. Optimistic locking is not enough because it leaves out requirements necessary to achieve isolation. Pessimistic locking can fix Hudi’s problems, but it isn’t recommended because the entire write operation must be done while holding the lock. In other words the concurrency fix is to disable concurrency.
Hudi’s guarantees undoubtedly raise more questions than I’ve covered. The spec has conventions for other features, like compaction, with different rules that I didn’t examine closely. More complexity means more issues.
Hudi may also have checks or workarounds for the issues I pointed out in my analysis. If it does, they’re not in the spec — I’ve had to draw on my experience to fill in gaps where I could and there are still many open questions.
Hudi’s spec doesn’t have enough detail to justify the project’s longstanding claims about concurrency guarantees. The project fixes concurrency problems as they come up. The problem with that approach is that you don’t know what you don’t know. There are always more flaws lurking.
The Importance of Consistency
Consistency is arguably the most difficult and most important ACID property. Consistency has two requirements – that:
- Modifications have the same behavior under concurrent conditions that they would if every change occurred one after another (that is, serially).
- Modifications never violate guarantees like foreign key or uniqueness constraints.
This definition is important when evaluating designs because Hudi and Iceberg take different approaches to separating responsibility between query engines and the table format. Iceberg considers consistency guarantees the responsibility of the query engine to declare, while Hudi includes row uniqueness constraints in the format spec.
Keeping this in mind helps to avoid superficial apples-to-oranges comparisons. The standard I use is how well the formats meet the definition above while embedded in compute engines. Are there cases where behavior differs under concurrent conditions?
One more thing to note is that consistency is hard to separate from isolation and atomicity guarantees. Without these guarantees, transactions can base changes on dirty or partial reads that destroy consistency. Consistency and isolation often blend together as isolation levels with different guarantees in compute engines.
Consistency in Hudi
Hudi includes a major consistency requirement in the format: Hudi tables can have a uniqueness constraint on the primary key and partition. When a record is written to a Hudi table with this requirement, Hudi requires that the new record replace the previous record. That is, all writes become row-level UPSERTs within a partition.
There is a procedure defined in the Writer Expectations [ref] for ensuring uniqueness:
- Find the latest instant in the timeline and choose an instant for the commit that is being attempted.
- Tag each incoming record with the file ID where the current copy of the record is stored. New records will have no tag.
- Write files into the table.
- For copy-on-write, rewrite data files by file ID and merge the UPSERTs.
- For merge-on-read, write a new log (delta) file for each file ID.
- Write deletes using a special log (delta) format with only deleted keys.
- Once all writes are complete, run concurrency control checks to ensure no overlapping writes. If checks succeed, complete the commit.
- Update indexes and metadata in the same transaction that commits the table modifications.
There are gaps that require some reasonable inferences:
- Deleted records should also be tagged to know the file ID the delete should target.
- For copy-on-write mode, apply deletes when rewriting files rather than creating deltas.
- For both write modes, write records with no tag into new base files with new file IDs.
- When locking, acquire the lock at the start of step 5 and release it after step 6.
From the Writer Expectations section alone, it’s unclear what the concurrency control checks in step 6 are doing, but the section on Concurrency Control with Writes has more [ref]:
If there are only inserts to the table, then there will be no conflicts. . .
Conflicts can occur if two or more writers update the same file group and in that case the first transaction to commit succeeds while the rest will need to be aborted and all changes cleaned up. To be able to detect concurrent updates to the same file group, external locking has to be configured. . .
Under optimistic locking, the table writer makes all new base and log files and before committing the transaction, a table level lock is acquired and if there is a newer slice (version) on any of the file groups modified by the current transaction, the transaction has conflicts and needs to be retried. . .
From this, you can see that the checks for concurrent modification operate on the file level by checking the file ID (which identifies a file group). After acquiring the table lock, the writer checks for committed instants newer than the instant on which changes were based. If there are new commits, it finds data or log files associated with those commits to get a list of file IDs that were modified concurrently. Then the check compares the set of file IDs modified by the current commit attempt with the set of file IDs that were modified concurrently. If there is any overlap, fail. Otherwise, complete the commit.
Hudi can miss duplicate rows
The question that first struck me when reading the Hudi spec is: how does Hudi guarantee row uniqueness when inserting records?
This appears to be a fundamental flaw in the spec in two places:
- Writer Expectations, Step 2: “New records will not have a tag”
- Concurrency Control with Writes: “If there are only inserts to the table, then there will be no conflicts”
When two concurrent writers insert the same key, each writer will find no current file ID with which to tag the inserted keys. Each writer will generate a new file ID for the inserted rows that will not conflict with the other’s new file ID. The second quote from the spec confirms this behavior by stating clearly that inserts do not conflict.
Initially, I was skeptical that a design flaw like this could have persisted in Hudi for multiple years. But running a simple test confirmed the problem that concurrent inserts will duplicate rows — even with optimistic locking turned on — and as designed Hudi cannot enforce its uniqueness guarantee.
Timeline inconsistency in Hudi
The next consistency problem stems from the design of Hudi’s timeline. Hudi associates files with a particular commit by embedding the commit instant in file names. A direct result of this design decision is that the instant for a commit cannot easily be changed. Updating the commit instant would require renaming every file created by the commit. And it’s worse in modern object stores, where a rename is implemented by making a copy and then deleting the original.
This leaves Hudi with a difficult runtime choice: what should a writer do when it encounters a completed commit with a later instant in the timeline? It could fail, but the work done by the writer would be lost. It could also continue with the commit (assuming it detects no conflicts), but that results in commits that are out of order in the timeline.
The Hudi spec doesn’t require detection or failing the commit, and testing confirmed that concurrent commits will complete. This choice makes some sense: choosing to fail would mean that each commit causes concurrent writers to abort and retry the entire write operation. Like pessimistic locking, that removes any benefit of concurrency. In practice, it would be worse than pessimistic locking because write attempts would waste resources.
There are two major consequences of the design choice to allow commits to be out of order in the timeline.
- Instants or versions of the table are not immutable. As a result, query results may change and time travel to debug those results is not accurate or reliable.
- Incremental consumers can miss commits by keeping track of state using the last instant consumed in the timeline. Testing confirms that some concurrent commits are indeed skipped when consuming a Hudi table from Spark streaming.
Missed records in Hudi incremental consumption
This experimental observation — that concurrent writes cause consumers to miss data — recently stirred up trouble and I was pointed to the Hudi FAQ answer on out-of-order commits [ref]. According to the FAQ, Hudi consumers work around this problem by consuming a commit only if there are no uncommitted operations before its instant. This worked most of the time, but I was able to get Hudi to skip records, so it isn’t perfect. Let’s see why that can happen.
Here’s a scenario that illustrates the problem: when a concurrent commit chooses an instant but doesn’t immediately write an instant file to the timeline. There are many potential causes:
- A 503 “slow down!” response from S3 that significantly delays file creation.
- A long GC pause (or other unexpected delay) at the wrong time.
- Clock skew. Object stores reject requests if they detect clock skew that is too large, but small skew can still cause issues.
- A client using the wrong time zone to produce the instant string.
Checking for a file in the timeline only provides safety if there is a mechanism that enforces the assumed happens-before relationship between timeline instant files. But without a mechanism like locking to enforce it, anything can — and apparently does — happen.
In addition, an unintended consequence of this workaround is that a failed writer could cause consumers to block indefinitely, waiting for the writer that crashed to clean up its timeline files. And fixing a blocked reader raises yet more problems: how does a process or an admin know that the writer has actually failed and is not just taking a long time? Guessing wrong would cause the reader to ignore a commit.
Mutable timeline instants in Hudi
Even assuming the workaround for incremental consumption succeeds, it is not documented in the spec and normal table reads are affected. According to the spec’s Reader Expectations [ref]:
Pick an instant in the timeline (last successful commit or . . .)
. . . file slices that belong to a successful commit before the picked commit should be included . . .
Readers are expected to ignore uncommitted instants. As a result, reading the same instant at different times can give different results. Those differences are another source of correctness problems. For example, what if you wanted to use an Airflow sensor to detect new batches of data arriving as partitions and trigger processing jobs? A straightforward approach is to periodically check the table for new partitions, using the latest instant as a high watermark. It’s easy to implement this in a way that accidentally skips data that arrives in the past by filtering on the instant.
Think of it this way: if a process naively relies on the Hudi timeline as an actual transaction log, false assumptions about ordering can easily lead to missing data.
Other patterns to consume data also skip records. Ironically, the approach that I recommend for CDC that achieves transactional consistency uses a transaction ID watermark in commit metadata. That is unsafe in Hudi.
Time travel with mutable instants is unreliable
The FAQ answer about out-of-order commits also confirms that time travel queries are affected:
Since most time travel queries are on historical snapshots with a stable continuous timeline, [a workaround] has not been implemented
The argument that most tables are written by a single writer is not convincing to me. Time travel is a case where reliable versions are especially important because it is often used for debugging. If you’re debugging a consistency problem with a pipeline, you want to know exactly what a query read from a table, not what it might have read depending on when, exactly, the query ran.
Hudi’s read-optimized view hallucinates table states
Hudi’s design introduces at least one more consistency problem: the read-optimized view.
For backward-compatibility with readers that can only consume Parquet files, Hudi exposes a “read-optimized” view of a table that reads only base Parquet files and ignores log (delta) files. This is only mentioned in the Hudi spec in passing, but comparisons of engine support often list compatibility based on reading the read-optimized view.
The problem is that the read-optimized data doesn’t necessarily correspond to a valid instant in the table. Base files can be created by new rows at any time, in the same commits that use delta/log files to replace or delete existing rows. Reading just the base Parquet files shows only partial changes from those commits.
I don’t think that most consumers understand that the “read-optimized” version exposes table states that never existed. This is particularly risky when there are regulatory requirements like GDPR or CCPA. Do people realize that, by ignoring deletes, “read-optimized” conflicts with the right to be forgotten?
Consistency in Iceberg
Iceberg’s approach is to provide reliable building blocks that engines use to make consistency guarantees about the behavior of commands such as MERGE, UPDATE, and INSERT that modify the table. Unlike Hudi, Iceberg doesn’t claim to guarantee row uniqueness — that’s done by using write patterns such as MERGE instead of INSERT.
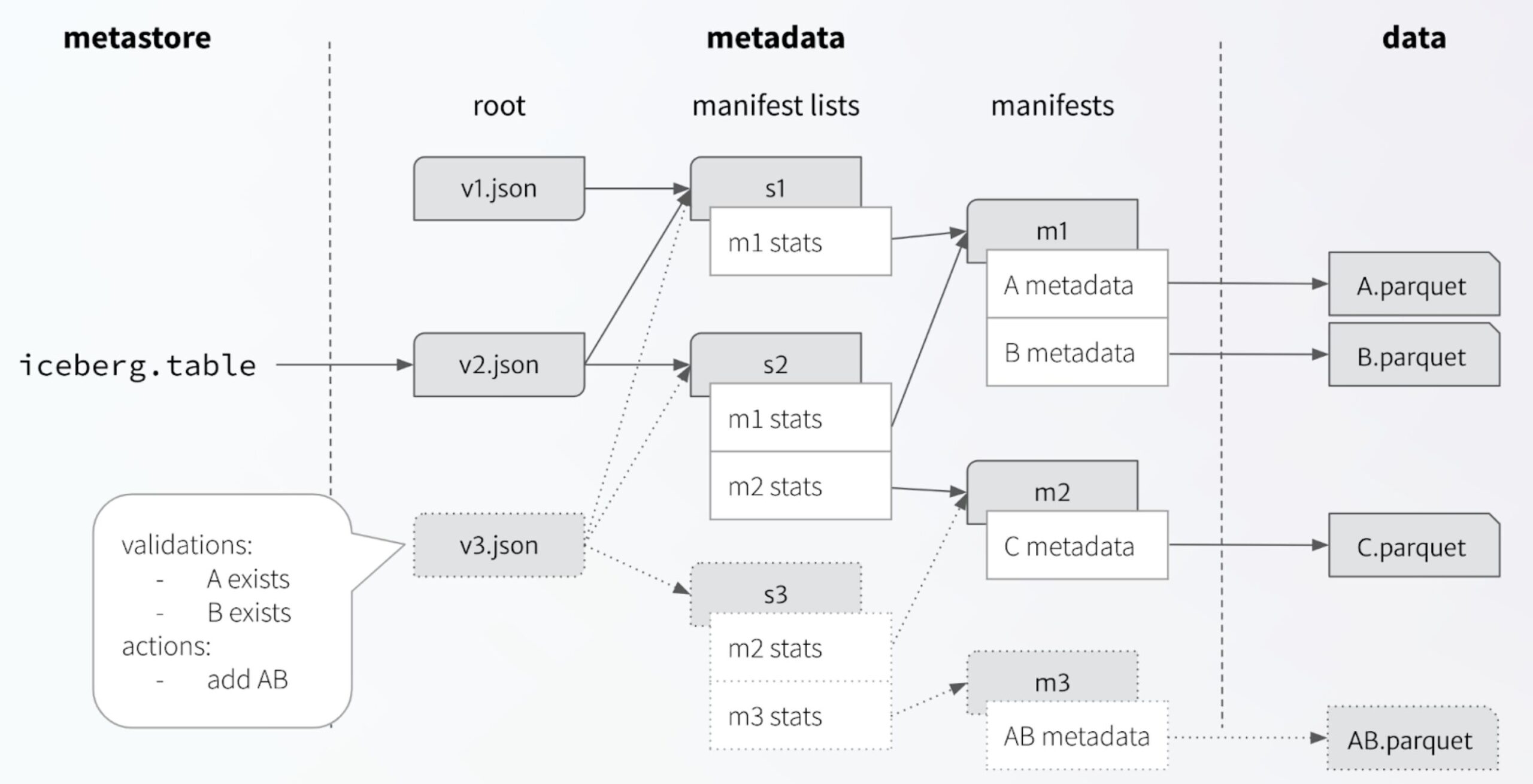
Iceberg’s building blocks start with the guarantees from the commit process. Every commit replaces some expected table state with a new table state. If the expected table state was out of date on the client, the commit fails and the client must retry. That’s the first part of how Iceberg achieves the same behavior under concurrent conditions: any concurrent modification to table metadata causes the atomic swap to fail and forces the client to reattempt (or give up). This produces a linear table history.
Iceberg’s metadata tree structure enables clients to reuse data files without moving or rewriting them during a commit retry. When a concurrent write fails because another writer updated the table first, only metadata files need to be rewritten and Iceberg checks to ensure that as much work as possible is reused from earlier commit attempts. This model allows Iceberg writers to work concurrently but still produce immutable table versions, called snapshots.
Next, Iceberg enables engines to make different consistency guarantees depending on their isolation levels and how they implement operations (such as copy-on-write vs. merge-on-read). The Iceberg spec imposes no requirements, as long as the new table state is well-formed. However, the Iceberg library provides important tools that engines use to run the validations they decide are necessary.
The library structures each commit as a series of actions and a set of requirements. The actions are operations such as add or remove a data file. The requirements are checks that must be true for the library to continue with a commit attempt. When an Iceberg commit succeeds, the library guarantees that the requirements/validations were all met by the snapshot that was replaced.
This makes it simple for an engine to configure Iceberg and provide consistency. For example, if files A and B are compacted into file AB, the consistency requirements are that A and B exist and the actions are to remove A and B, then add AB. Iceberg will guarantee that A and B exist or will fail. The requirements can get more complicated, like checking that no new data was added that matches a particular filter expression, which is needed to validate an UPDATE or DELETE.
Comparing consistency guarantees
In looking into Hudi’s consistency guarantees, I found serious design flaws and was able to validate those flaws in testing.
- As written, Hudi’s spec cannot guarantee row uniqueness under concurrent conditions.
- Hudi table versions (instants) are mutable and may change under concurrent writes.
- Mutable instants lead to skipped data in incremental and batch read patterns.
- Time travel may produce different results than queries that read the same instant.
- Querying the read-optimized view of a table reads a state that may never have existed.
These all violate the standard definition of database consistency, though I should note that row duplication violates a guarantee that is unique to Hudi. In addition, Hudi once again has a much larger surface area than I’ve analyzed.
In comparison, Iceberg’s model forces concurrent writers to retry and reconcile their changes on top of the current table state. Iceberg’s metadata enables more reuse and avoids the need to make table versions mutable.
ACID vs _ _ _D
When Dan Weeks and I created Iceberg, our primary goal was to enable multiple engines to operate independently on Netflix’s data lake safely. That’s a critical building block of a data architecture — without it you can’t trust query results. One of the earliest choices we made was to drop compatibility with the Hive table format. Hive’s biggest flaw was tracking table state using a file system. We knew that we wouldn’t achieve strong ACID guarantees by maintaining that compatibility; we’d be applying band-aid fixes one after another. ACID guarantees must be built into the table format’s basic design.
The Hudi community made different choices. Hive compatibility was important to them and is why, even now, the log/delta files use hidden file names: so that any Hive-compatible framework could use the “read-optimized” table view. Starting from the Hive format and evolving has naturally shaped the result. This evolutionary approach only goes so far because it’s iterative and is still limited by Hive’s architecture. When you squash correctness bugs as they come up, not seeing more bugs doesn’t mean there aren’t any more.
To the Hudi community’s credit, they’ve squashed a lot of correctness bugs. The problem is that the complexity that has built up makes it impossible to conclude there aren’t any more bugs lurking. More importantly, it becomes extremely difficult to document, let alone implement, the standard fully. Plus, it implies the standard will be a moving target as new bugs are squashed.
Many of the issues I pointed out in my analysis can be solved. The gaps in the spec can be filled in. But that level of analysis needs to be done for compaction and the other parts of the spec that have special procedures, too. If that were done, would it be enough?
I don’t think that the iterative approach is a reliable path to ACID guarantees. It’s just not a solid foundation on which to build data infrastructure. That’s why engines such as BigQuery, Snowflake, Redshift, Athena, Starburst, Dremio, and Impala are focusing on Iceberg — the Iceberg spec is straightforward, complete, easier to implement, and delivers the guarantees that these engines rely on.


