
A result of Iceberg’s nature as an open table format is strong interoperability across many compute engines. This blog post walks through an example of this interoperability. Using a single shared catalog, both Flink and Spark can operate on the same Iceberg warehouse, providing the powerful streaming capabilities of Flink along with the feature-rich batch framework provided by Spark.
Overview
Instead of connecting to an external source, such as a Kafka topic, this demo will use a Flink app that generates data on its own using Flink’s native support for rich functions. The data will come from the java-faker library which allows generating Lord of the Rings data among many other categories.
Let’s jump right in!
Launching the Docker Environment
To launch the docker environment, clone the docker-spark-iceberg repository that includes various demo setups for Iceberg and change into theflink-example directory.
git clone [email protected]:tabular-io/docker-spark-iceberg.git
cd docker-spark-iceberg/flink-example
Start the docker environment using docker compose.
docker compose up
Once the docker environment has started up, you can access the notebook server, MinIO UI, and Flink UI all on localhost.
- Spark-enabled Notebook Server: http://localhost:8888
- MinIO UI: http://localhost:9000
- Flink UI: http://localhost:8081
Building the Flink App
The Flink app included in the flink-example directory comes ready to build and deploy. You can build the app using the gradle shadowJar plugin.
./gradlew clean shadowJar
Once the build has completed, the app jar can be found at build/libs/flink-example-0.0.1-all.jar.
Creating the Database
Before running the Flink app, create a database named lor using a Spark notebook. To launch a Spark notebook, navigate to the notebook server at http://localhost:8888 and create a new Python3 notebook.
Using the %%sql magic that’s included, run a CREATE DATABASE command in the first cell.
%%sql
CREATE DATABASE lor
Submitting the Flink App
The Flink app, given a target table, will create the table using the Iceberg Java client with the following schema:
characterstringlocationstringevent_timetimestamp
The app will then begin generating and streaming data, appending the data to the target table at each checkpoint. The character and location values will come from the Lord of the Rings Faker and the event_time will be a randomly generated timestamp between five-hundred years ago and today.
Gandalf was spotted at Utumno in 1596??…very suspicious!
The Flink UI makes it convenient to submit a Flink app jar. Submit the example Flink app by navigating to the Submit New Job page and selecting the +Add New button.
Once the example Flink app has been added, select the app in the Uploaded Jars table to expand the app menu. In the Program Arguments box, add a --database "lor" and --table "character_sightings" parameter to specify a the target table for the stream.
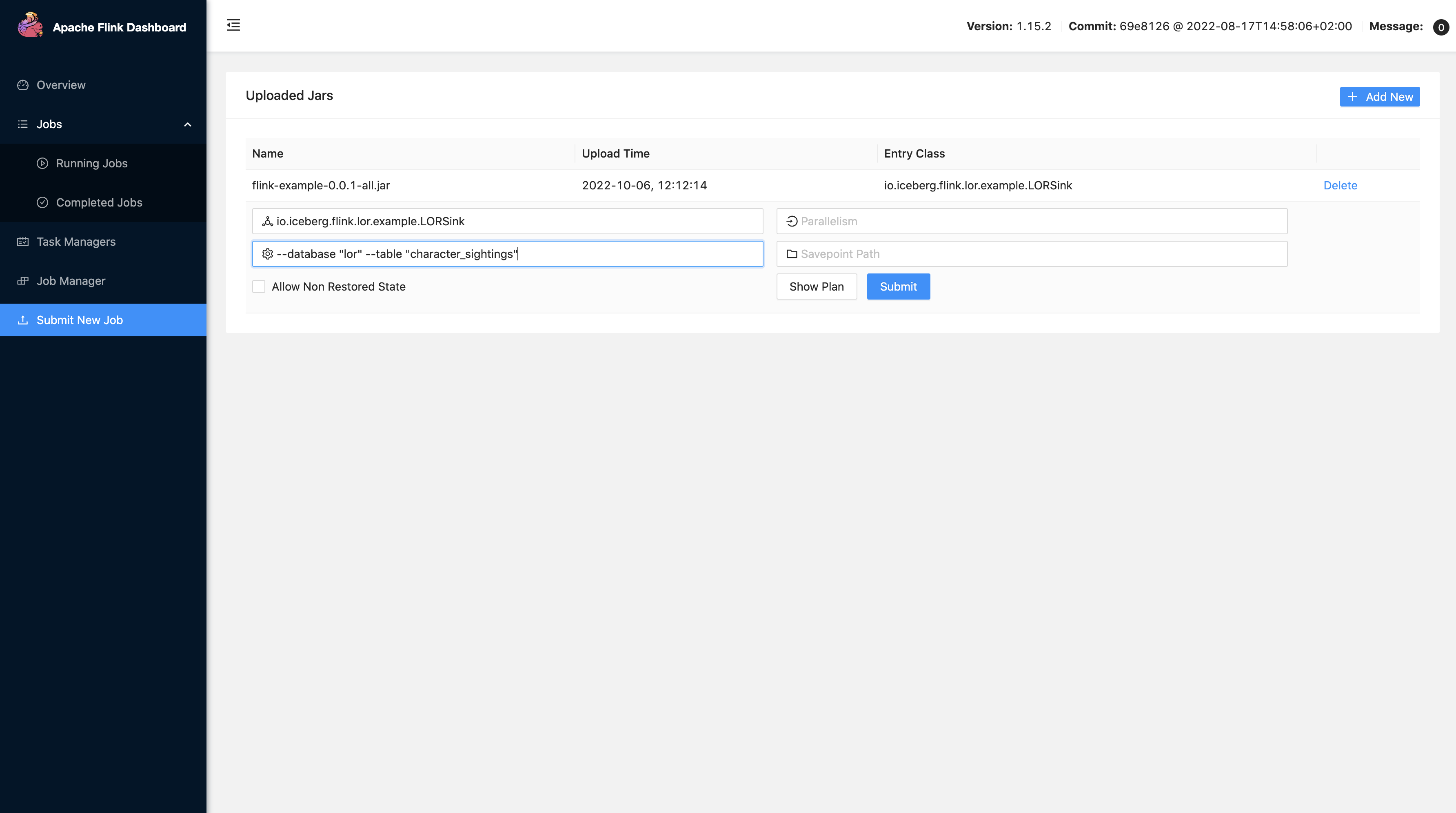
Click the submit button and the Flink app will begin streaming into the Iceberg warehouse stored in MinIO.
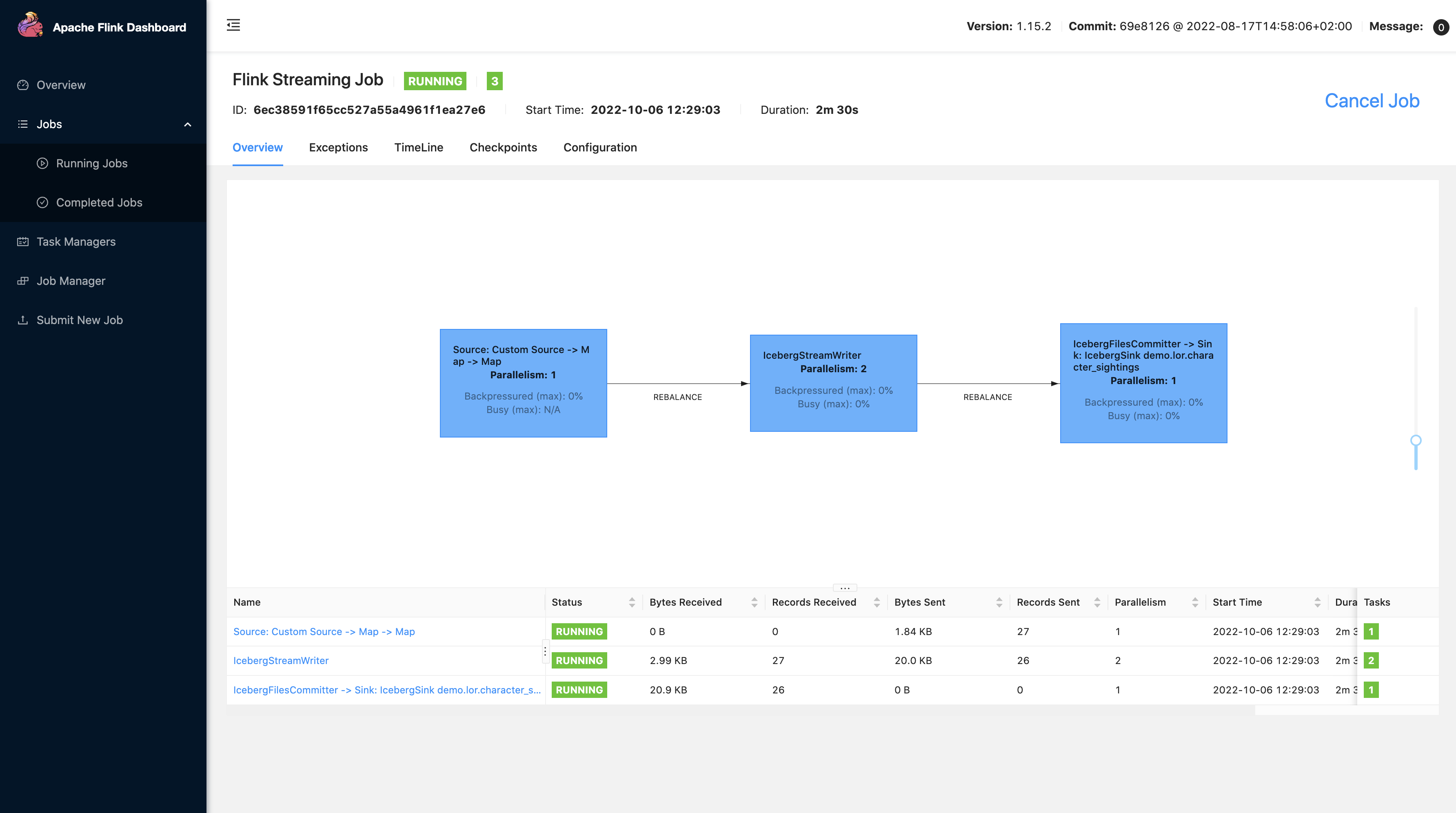
Now let’s query it from Spark!
Querying the Streaming Data in Spark
Now that the Flink app is streaming into the lor.character_sightings table, the data is immediately accessible to Spark apps since they both share a single REST catalog. Go back to the Spark notebook created earlier and perform a SELECT query to see the data.
%%sql
SELECT * FROM lor.character_sightings LIMIT 10
output:
+----------------+-------------------------+-------------------+
|character |location |event_time |
+----------------+-------------------------+-------------------+
|Grìma Wormtongue|Bridge of Khazad-dûm |1931-08-01 09:02:00|
|Bilbo Baggins |Ilmen |1693-08-01 03:06:28|
|Denethor |Barad-dûr |1576-01-04 17:01:59|
|Elrond |East Road |1738-09-04 08:07:24|
|Shadowfax |Helm's Deep |1977-06-10 00:28:44|
|Denethor |Houses of Healing |1998-02-08 12:09:05|
|Quickbeam |Warning beacons of Gondor|1674-05-25 06:12:54|
|Faramir |Utumno |1801-04-14 00:09:19|
|Legolas |Warning beacons of Gondor|1923-02-21 10:24:55|
|Sauron |Eithel Sirion |1893-05-21 01:29:57|
|Gimli |Black Gate |1545-03-06 20:51:13|
+----------------+-------------------------+-------------------+
A Closer Look at the Example Flink App
The Flink app included in this demo performs four main steps. First, It creates a catalog loader that’s configured to connect to the REST catalog and the MinIO storage layer included in the docker environment.
ParameterTool parameters = ParameterTool.fromArgs(args);
Configuration hadoopConf = new Configuration();
Map<String, String> catalogProperties = new HashMap<>();
catalogProperties.put("uri", parameters.get("uri", "http://rest:8181"));
catalogProperties.put("io-impl", parameters.get("io-impl", "org.apache.iceberg.aws.s3.S3FileIO"));
catalogProperties.put("warehouse", parameters.get("warehouse", "s3://warehouse/wh/"));
catalogProperties.put("s3.endpoint", parameters.get("s3-endpoint", "http://minio:9000"));
CatalogLoader catalogLoader = CatalogLoader.custom(
"demo",
catalogProperties,
hadoopConf,
parameters.get("catalog-impl", "org.apache.iceberg.rest.RESTCatalog"));
Secondly, the app creates an Iceberg schema for the output table that contains three columns, character, location, and event_time.
Schema schema = new Schema(
Types.NestedField.required(1, "character", Types.StringType.get()),
Types.NestedField.required(2, "location", Types.StringType.get()),
Types.NestedField.required(3, "event_time", Types.TimestampType.withZone()));
Catalog catalog = catalogLoader.loadCatalog();
String databaseName = parameters.get("database", "default");
String tableName = parameters.getRequired("table");
TableIdentifier outputTable = TableIdentifier.of(
databaseName,
tableName);
if (!catalog.tableExists(outputTable)) {
catalog.createTable(outputTable, schema, PartitionSpec.unpartitioned());
}
Thirdly, the Faker source is initialized and added to the stream execution environment. By default, checkpointing is set to 10 seconds and the interval at which a fake data record is generated is set to 5 seconds, but both can be overriden using the --checkpoint and --event_interval
parameters, respectively.
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(Integer.parseInt(parameters.get("checkpoint", "10000")));
FakerLORSource source = new FakerLORSource();
source.setEventInterval(Float.parseFloat(parameters.get("event_interval", "5000")));
DataStream<Row> stream = env.addSource(source)
.returns(TypeInformation.of(Map.class)).map(s -> {
Row row = new Row(3);
row.setField(0, s.get("character"));
row.setField(1, s.get("location"));
row.setField(2, s.get("event_time"));
return row;
});
Lastly, the app creates a flink sink configured to run in append mode and executed against the output table.
// Configure row-based append
FlinkSink.forRow(stream, FlinkSchemaUtil.toSchema(schema))
.tableLoader(TableLoader.fromCatalog(catalogLoader, outputTable))
.distributionMode(DistributionMode.HASH)
.writeParallelism(2)
.append();
// Execute the flink app
env.execute();
Closing Remarks
As an open table format, Iceberg is truly engine agnostic which allows utilization of the right tool for the right job. Instead of settling for a single compute engine and accepting a set of tradeoffs, Iceberg brings the strengths of all compute engines to your data warehouse. Additionally, each compute engine can rely on, and benefit from, all of the powerful maintenance features of Iceberg tables such as compaction, snapshot expiration, and orphan file cleanup.
This blog post covered Spark and Flink but there are many other compute engines and platforms that support Iceberg and the list continues to grow rapidly. Head over to the documentation site to learn more about Iceberg and check out the community page to see all of the ways you can join the Iceberg community!


